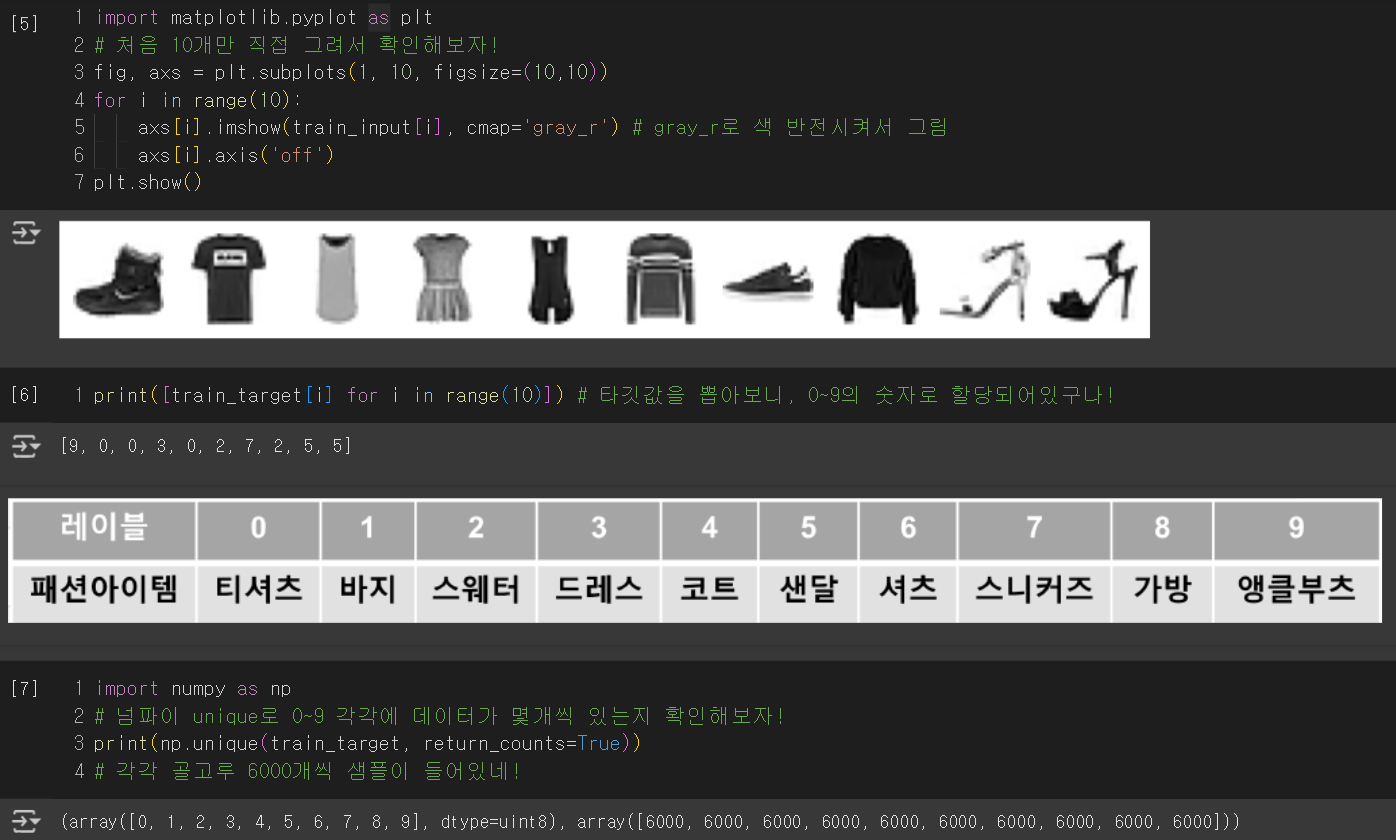
• 필터를 64개 썼으니, 특성 맵의 깊이는 64가 될 것 • (2,2) 풀링 썼으니, 특성 맵의 크기는 절반으로 줄어들 것 ⇒ 여기까지 통과한 특성맵 : (7, 7, 64)
5) Flatten - Dense - Dropout
최종 출력층으로 가기 전에 은닉층을 하나 거쳐가도록 추가
완전연결층으로 연결하기 위해 `Flatten` 층을 추가 = 1차원으로 펼침
은닉층 뉴런 개수는 100개로 설정
Overfitting 막기 위해 `Dropout` 층도 추가. 40% 확률로 노드 off.
# 이제 최종 확률값을 구하기 위해, Dense층 거쳐야 함!!
model.add(keras.layers.Flatten()) # 3차원 특성맵을 1차원으로 펼침
model.add(keras.layers.Dense(100, activation='relu')) # 뉴런 100개짜리 "은닉층"
model.add(keras.layers.Dropout(0.4)) # 오버피팅 규제를 위해서 드롭아웃 층도 추가
6) Dense
최종 출력층은 `softmax` 함수 사용 = 10개의 클래스에 대한 분류 확률을 출력!
# 10개로 구분하는 "출력층"으로 마무리!
model.add(keras.layers.Dense(10, activation='softmax')) # 다중분류니까 softmax 함수
keras.utils 패키지의 `plot_model` 함수를 쓰면 모델 구조를 그림으로도 출력 가능
❗그림에는 안 나오지만 InputLayer라는 층이 맨 앞에 자동으로 추가됨 (25년 2월 기준)
keras.utils.plot_model(model) # 출력 결과로 아래 그림이 나옴
# show_shapes 설정으로 입출력 크기도 같이 볼 수 있고, to_file로 모델 이미지 저장도 가능함!
keras.utils.plot_model(model, show_shapes=True, to_file='cnn-architecture.png', dpi=300)
전체 구조를 그림으로 그려보면 아래와 같음
3. 모델 컴파일 & 훈련
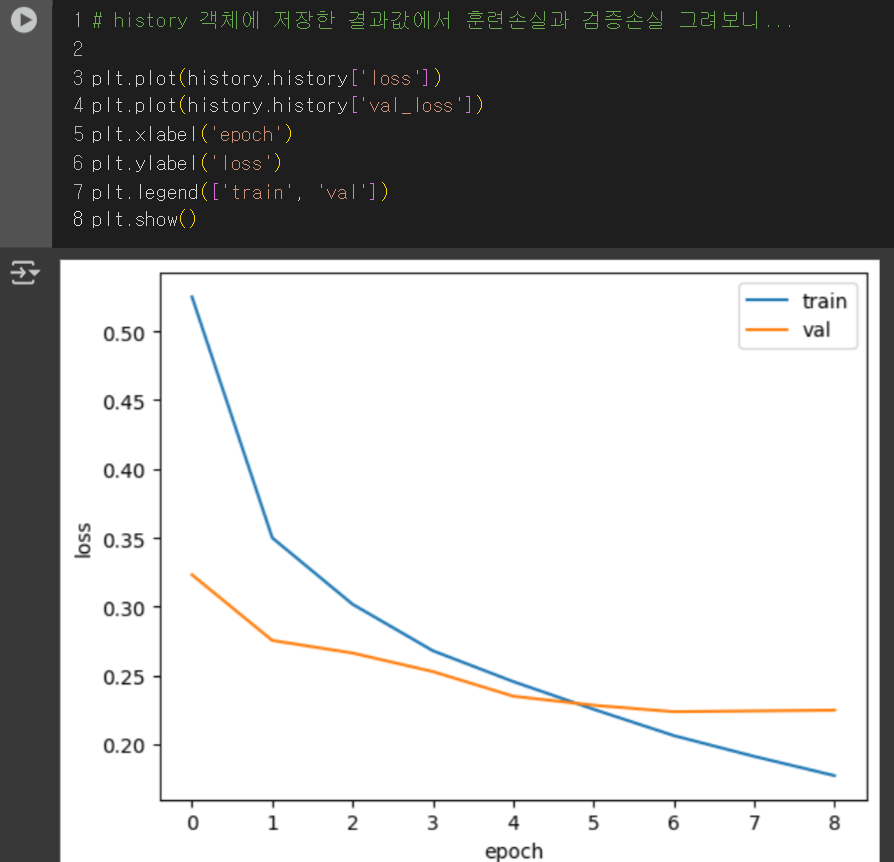
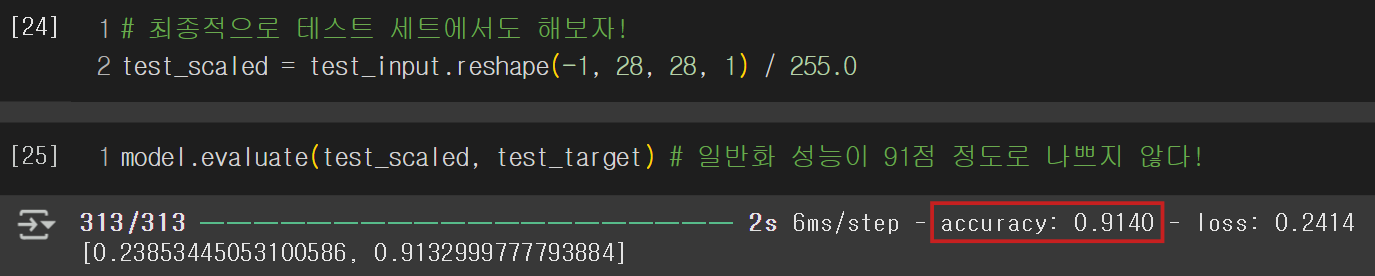
모델 구성을 완료했으니, 이제 컴파일 설정하고 훈련하자!
Keras의 장점: 모델 종류나 구성 방식에 상관없이 Compile & Fit 과정이 같아서 편리함!
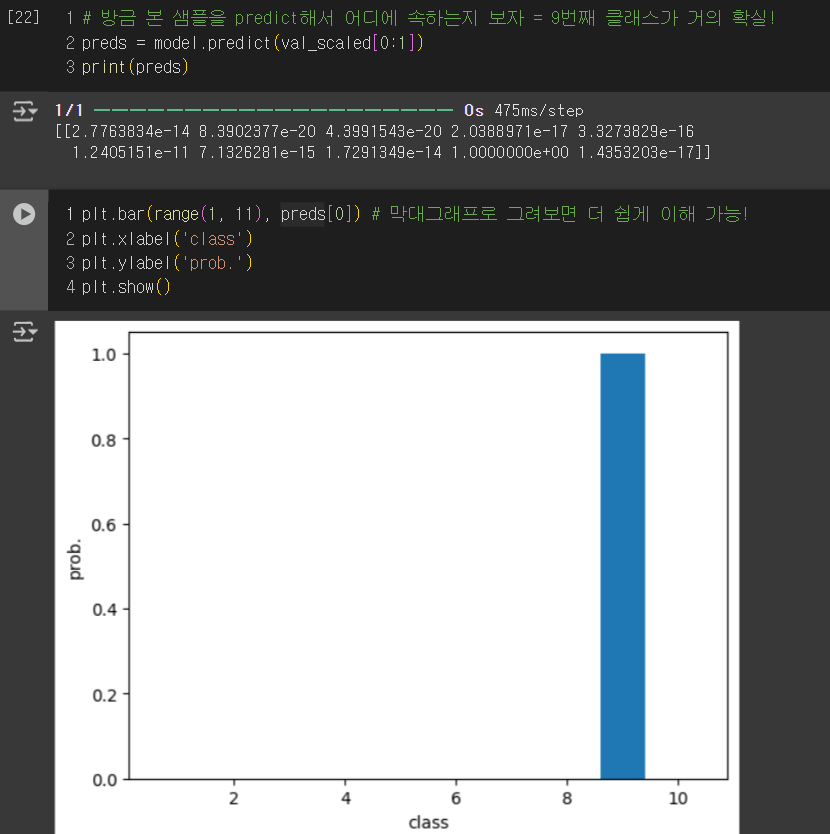
455p. 코드 [22]에서 첫 번째 샘플을 전달할 때 왜 `val_scaled[0]` 이 아니라 `val_scaled[0:1]` 를 사용하나요?
👨🏫Keras의 fit, predict, evaluate는 모두 배치(batch) 형태의 입력을 기대합니다. (여러 개의 샘플을 한 번에 처리하는 게 일반적이기 때문) 그래서 하나의 샘플을 전달하더라도 리스트를 하나 더 감싸서 (=배치 차원을 그대로 유지한 상태로) 전달해야 합니다. 🆗 [0]은 단순히 첫 번째 원소를 선택하는 것이므로 차원이 하나 줄어듦. 반면 [0:1]는 첫 번째 원소만 포함하는 '부분집합'을 만드는 거니까 원래의 차원(shape)이 유지되면서 첫 번째 차원의 크기만 1이 됨. 아래의 간단한 예시로 이해할 수 있음.