옵티마이저도 하이퍼파라미터 중 하나로,경사하강법의 종류에 대한 설정임. ex) `SGD()`: 이름은 그냥 SGD인데 실제로는 미니배치 경사하강법 (기본 배치크기 = 32)
설정(compile) 단계에서 `optimizer`로 지정할 수 있으며, [16]처럼문자열로 호출하거나, [17]처럼객체로 만들어놓고 호출할 수도 있음
우리가 배웠던 SGD 이외에도 더 개선된 방법들이 많음! (p.382)
적응적 학습률: 최적점에 가까워질수록 학습률을 낮추는 효율적인 방식
"이 옵티마이저들이 어떻게 최적화하는지에 대한 자세한 내용은 중급자 교재로...^^"
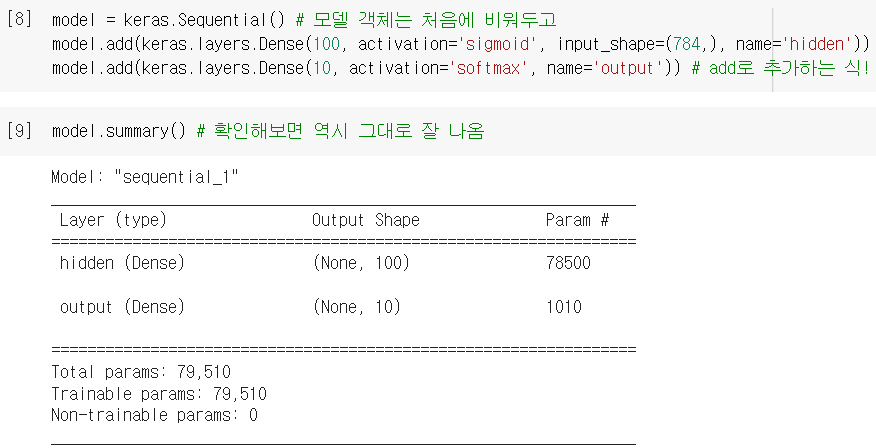
심층신경망 만들기 (5)
자 그럼 우리는, Adam 옵티마이저를 사용한 모델로 최종 모델을 만들어보겠음! ( 역시 `Sequential` & `add` → `compile` → `fit` → `evaluate` 순서대로~ )
이제 여러 개의 층을 추가한 다층 인공 신경망까지 터득 완-료!
➕플러스 알파
➊ 회귀 신경망 모델의 활성화함수
우리는 럭키백 문제를 다루니까 계속 인공신경망으로 '분류 모델'을 만들었다. 그렇다면, 회귀 문제에서는 어떤 활성화 함수가 쓰일까?
대답은"필요 없다"이다. 분류 모델에서 활성화 함수(ex. sigmoid, softmax)를 썼던 이유는, (알다시피) 확률로 출력하기 위해서였다. 그런데 회귀의 출력값은 그냥 임의의 숫자값이 그대로 나오는 것이므로, `activation`에 아무것도 지정해주지 않으면 된다!
➋ Flatten 층
뭔가 의미 있는 연산을 하는 게 아니라 그냥 편의를 위한 기능뿐이라서 '층'이라고 하기도 좀 애매하지만, 그래도 `keras.layers`모듈 아래에 있어서 '층'이라고 한다.
케라스 API는 입력 데이터에 대한전처리 과정을 최대한 모델 내에 포함시키려는 추세인데, 그러한 일환으로 보면 되겠다.
➌ 앙상블 알고리즘🆚심층 신경망
여러 개를 모아서 하나의 최종 모델을 구성한다는 점에서비슷해보이지만, 완전히 다른 방식으로 훈련된다!
🤔 Hmmmm...
370p. 시그모이드는 그냥 0~1로 압축해주는 역할이었음. 근데 얘를 중간에 끼워넣는다고 성능이 좋아지는 이유가 뭐지?
👨🏻🏫 활성화 함수를 사용하는 이유는 369페이지 설명을 참고하세요. 🆗 아 그러네요 착각했습니다^^;; 성능이 좋아지는 건 활성화함수가 아니라 층을 쌓았기 때문..! 활성화함수는 그저 출력값의 존재가 무색해지지 않게 비틀어주는 것뿐! (본문 #3-1 참고)
그렇다면 질문을 바꿔서 드려야하겠네요. 그냥 똑같은 종류의 Dense 층을 하나 더 쌓았을 뿐인데 성능이 좋아지는 이유가 궁금합니다! 한번에 10개의 유닛(z)으로 가는 게 아니라, 100개의 h를 거치고 다시 10개의 z로 가니까 더 특징을 잘 잡아낸다 정도로 이해하면 되는 걸까요..?
377p. 렐루함수는 z가 양수일 때 z를 그대로 쓰는데, 그러면 활성화함수로서의 의미가 없는 게 아닌가요? 오히려 시그모이드 함수는 지수함수를 써서 비선형적으로 틀어줬는데, 왜 더 단순한 렐루함수가 유용하게 쓰이는 건지요ㅠ (음수는 걍 무시해버리는데 이것도 괜찮은 건지,,)
376p. 경사하강법에서 점진적으로 학습하려면partial.fit으로 훈련시킨다고 배웠습니다. 그런데 제가 우연히 <run>을 잘못 눌러서fit으로 한번 더 훈련시켰는데 성능이 높아지는 것을 발견했습니다. 혹시 이건 왜 그런 걸까요?
👨🏻🏫 케라스에서는fit()메서드가 점진적인 학습 방법입니다. 🆗 오호라!
384p. 고급 옵티마이저인 Adam을 사용했는데도 성능이 거의 동일하게 나온 이유가 궁금합니다. 혹시 성능은 비슷한 대신 시간이 더 줄어드나요?
👨🏻🏫 어떤 옵티마이저가 항상 더 나은 성능을 낸다는 보장은 없습니다. 🆗 그래.. 그냥 해당 문제에 더 잘 맞냐 안 맞냐가 있는 거겠지..!
🤓 To wrap up...
지난 시간에 배운 신경망에서 층을 추가하는 방법을 배웠다. 그러니 사실상 이제서야 신경망의 기본적인 형태를 배운 셈..! 다만 여러가지 고급 옵티마이저들을 보니 또 할 게 많이 남았다는 생각이 밀려온다 🥲 저스트 킵 고잉 ..
여전히패션 럭키백을 만드는데, 지난 번에 만든 인공신경망을 더 업그레이드 하기로 함! =심층신경망→ 이번엔 입력층과 출력층 사이에은닉층이라는 걸 하나 추가함! →층 추가하는 방법(1)객체로 만들고 전달(2)Sequential 내에서 바로 생성(3)객체는 아니고add 메소드로 전달 → 시그모이드 활성화함수의 단점을 극복한렐루 활성화함수를 새롭게 도입 + 입력데이터를 일렬로 펼쳐주는Flatten 층도 새로 도입 → 확실히 성능 좋아짐! → 더 나아가, 하강법의 종류를 설정해서 성능 더더욱 높일 수 있는옵티마이저까지 배움!