
데이터마이닝에 관한 스터디를 진행하고자 정리한 내용입니다. 참고한 자료들은 아래에 따로 정리해두었으며,개인 공부 과정에서 틀린 부분이 있을 수 있습니다. (잘못된 부분은 알려주시면 수정하겠습니다!)
Intro.
지난 스터디에서는 트리 알고리즘의 기본적인 학습 과정을 배웠습니다. 트리 알고리즘의 핵심은 아래 2가지 질문으로 볼 수 있었는데, 지난 시간에 배운 내용은 그 중에서 "어떻게 분기할 것인가"에 대한 내용이었습니다.
🔑Key Ideas in Decision Tree (트리 알고리즘의 핵심이 되는 2가지 질문)
1. 어떻게 분기할 것인가?
▶ 1회성 분기가 아니라, 반복적으로 분기하자! = 재귀적 분기(Recursive Partitioning)
▶ “잘” 분기하자! = 정보이득이 커지는 방향으로! (분류는 불순도가 낮아지게! 회귀는 RSS가 작아지게!)
2. 어디까지 분기할 것인가?
▶ 과적합 되기 전까지만 분기하자! = 사전 가지치기 (pre-pruning)
▶ 끝까지 분기한 뒤, 다시 적당히 합치자! = 사후 가지치기 (post-pruning)
그럼 이번 시간엔 “어디까지 분기할 것인가?”에 대한 내용을 보겠습니다. 지난 시간 학습 프로세스에서 보았듯이, 기본적으로 Decision Tree는 불순도 또는 RSS가 더 줄어들지 않을 때까지 분기한다고 했습니다. 하지만 이 Full-Tree는 훈련 데이터를 완벽히 학습한 것이고, 이는 노이즈의 정보까지 학습하게 되어 과대적합(overfitting) 문제를 야기합니다.
- 과대적합(overfitting) = Bias ↑ Variance ↓ = 새로운 데이터에 강건하지 못함(non-robust)
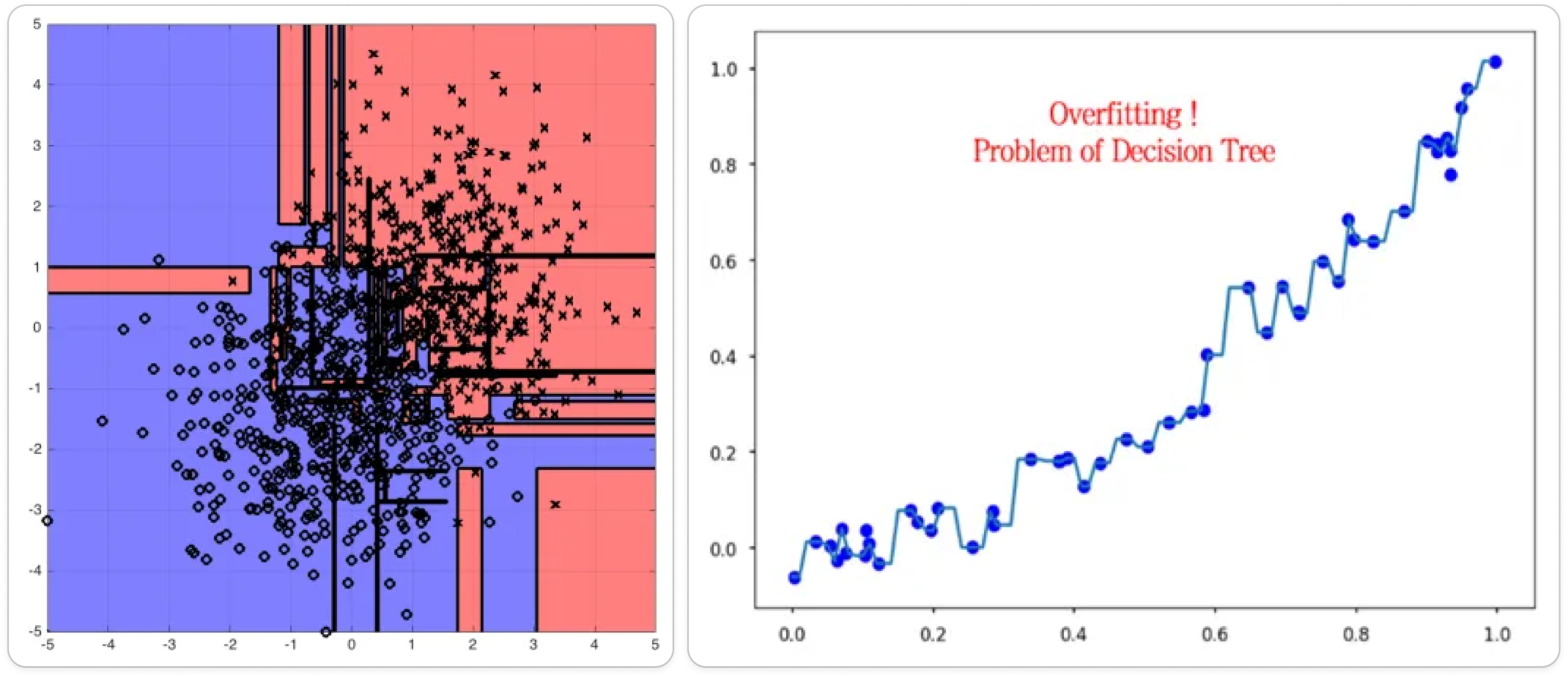
트리 모델에서 그러한 과적합을 방지하기 위해 ‘가지 치기(Pruning)’라는 작업을 수행할 수 있습니다. ‘가지 치기’란 Decision Tree의 분기 깊이를 적정 수준에서 제한하는 방법으로, Full-Tree까지 다 만들지 않겠다는 뜻입니다. 즉, 훈련 성능이 완벽하지 않더라도, 적당히 학습량을 조절하여 일반화 성능을 확보하자는 것이 ‘가지 치기’의 핵심입니다.

‘가지 치기(Pruning)’에는 대표적으로 사전 가지치기와 사후 가지치기가 있습니다. 사후 가지치기는 일단 Full-Tree를 만든 후, 적절한 수준에서 Leaf node를 결합해주는 방법입니다. 사전 가지치기는 트리의 깊이나 리프노드 내 최소 관측값 수를 미리 지정하여, 애초에 Tree가 일정 수준 이상 자라지 못하게 막는 방법입니다. 원래는 사후 가지치기가 먼저 제안됐는데, 계산 효율성 측면에서 많은 소프트웨어가 사전 가지치기를 구현하고 있습니다.
1. 사후 가지치기(Post-pruning)
1.1. REP (Reduce Error Pruning)
- 가장 기본적인 사후 가지치기 방법은 REP가 있습니다. 이는 트리를 완전히 성장시킨 후, 검증 데이터(validation set)를 사용하여 불필요한 노드를 제거하는 방법입니다.
- 구체적인 과정은 아래와 같습니다.
- 트리를 일단 최대 깊이까지 성장시킨다. (=모든 데이터를 100% 학습한 over-fitting 상태).
- 맨 밑에서부터 각 분할 지점을 돌아보면서 분할 이전과 이후의 검증 성능(ex. 정확도)을 비교한다.
- 분할 이전의 정확도가 더 높게 나오면, 해당 자식노드는 쳐낸다. (=즉, 가지치기 하고 검증 데이터로 성능 봤을 때 정확도 높아지면 가지치기 유지하고, 정확도 떨어지면 원래대로 분기하는 것)
- 위 과정을 반복하여, 최종적으로 가장 적절한 크기의 트리를 찾는다.
(리프 노드부터 시작해서 점점 가지치기를 수행하며 위로 올라감)
- 아래 예시의 경우, t3에서 분할 이후의 정확도가 분할 이전의 부모 노드 때보다 낮아진 것이 보이실 겁니다. (t2에서는 오분류율이 0이었는데, t3에서는 1/3로 증가함) ⇒ 이런 경우 t3의 자식노드를 쳐내고, 주황색 공이 6개 들어있는 노드를 리프노드로 바꿔주면 가지치기가 완료됩니다.

- REP 가지치기 방식의 장단점
- 👍알고리즘이 단순, 직관적이고 이해하기 쉽다
👍검증 데이터 성능을 기준으로 하므로 과적합 위험을 줄일 수 있다 - ❌검증 데이터를 따로 준비해야 해서 데이터 양이 적을 경우 활용이 어렵다 (+검증 데이터가 적으면 가지치기가 과도하게 진행될 수 있음)
❌ 노드를 하나씩 줄이고 평가하는 과정을 반복하므로 계산 비용이 크다
- 👍알고리즘이 단순, 직관적이고 이해하기 쉽다
1.2. CCP (Cost Complexity Pruning)
- 다음으로, CCP라는 방법이 있습니다. 이 방법은 아예 트리의 복잡도를 고려한 비용 함수(cost function)를 설정하고, 그 값을 바탕으로 가지치기할 노드를 결정합니다. (적절한 복잡도를 유지하는 방향으로)
- Cost Complexity(=비용함수)의 정의식은 아래와 같은데요. 쉽게 말하면, 원래 불순도 지표에서 트리의 복잡도에 관한 페널티를 부여하는 것입니다.
- Err(T) : 원래 우리가 알고 있는 불순도(gini, entropy, misclassification 등)를 의미하는 Error term
- L(T) : 리프노드의 개수 ⇒ 트리가 복잡할수록 커지는 penalty term
- α : 가지치기(=페널티) 강도를 조절하는 하이퍼파라미터
- "에러가 같다면 더 단순한 트리를 선택하겠다" & "리프노드 개수가 같다면 에러 낮은 트리를 선택하겠다" ⇒ 이 두 가지를 복합적으로 고려한 비용함수!

- 구체적인 과정은 아래와 같습니다.
- 트리를 일단 최대 깊이까지 성장시킨다. (=모든 데이터를 100% 학습한 over-fitting 상태)
- 비용 함수(Cost Complexity)를 계산하여 가지치기할 노드를 결정한다.
- α값을 점점 증가시키면서, α와 T(트리)의 조합을 구한다 (각 분할 지점마다 α*를 계산하여 최소인 경우를 택하는데, 구체적인 과정은 reference 참고)
- 교차검증(또는 검증데이터)을 통해 조합들을 비교하여 최적의 α값과 트리를 선택한다.
- CCP 가지치기 방식의 장단점
- 👍불순도를 최대한 유지하면서 가지치기를 수행하므로, REP보다 안정적인 트리를 얻을 수 있다.
👍scikit-learn에서 지원하는 공식적인 가지치기 방법이라 구현하기 쉽다. - ❌적절한 α값을 찾기 위한 반복 계산 때문에 비용이 크다.
❌모든 subtree를 고려하는 것이 아니라서 Local minimum에 빠질 수 있다.
- 👍불순도를 최대한 유지하면서 가지치기를 수행하므로, REP보다 안정적인 트리를 얻을 수 있다.
2. 사전 가지치기(Pre-pruning)
- 다음으로, 사전 가지치기는 트리가 지나치게 복잡해지는 것을 미리 방지하는 방법입니다. 즉, 불필요한 분할을 미리 차단해서 모델이 과대적합(overfitting)되는 것을 막는 것이죠.
- 주로 모델의 하이퍼파라미터로 설정하도록 되어있으며, 아래와 같은 종류가 있습니다.

2.1. max_depth (최대 깊이 제한)
- max_depth : 트리가 분기하는 최대 깊이를 제한
- 작은 값을 지정하면 얕게(조금) 분기하여 단순한 모델이 되고, 큰 값을 지정하면 깊게(많이) 분기하여 복잡한 모델이 됨
- 위 예시 그림에서도 `max_depth=2` 일 때 모델이 가장 단순하고, `max_depth=8` 일 때 모델이 가장 복잡해짐
2.2. min_samples_split, min_samples_leaf (최소 샘플 수 제한)
- min_samples_split : 노드를 분할 시 필요한 최소 샘플 개수를 제한
- ex) `min_samples_split=10`이면, 샘플이 10개 이상 있어야 그 노드를 분할할 수 있음.
- min_samples_leaf : 리프 노드가 가져야 하는 최소 샘플 개수를 제한
- ex) `min_samples_leaf=5`이면, 리프 노드에 최소 5개 이상의 샘플이 있어야 유지됨.
2.3. min_impurity_decrease (정보 이득 하한선 설정)
- min_impurity_decrease : 정보이득이 일정 수준 이상일 때만 노드를 분할하도록 제한
- ex) `min_impurity_decrease=0.01`이면, 그 노드를 분할했을 때 불순도가 0.01 이상 감소해야 분할 가능함.
이러한 여러 하이퍼파라미터 값을 교차검증으로 비교하며 가장 좋은 성능을 도출하는 모델을 선택하면 됩니다. 표로 내용을 정리하면 아래와 같습니다.

3. 코드로 구현하기
3.1. REP
- 일단 트리를 완전 성장시킨다
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
# 데이터 로드 및 분할
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# 트리 학습 (완전 성장)
tree = DecisionTreeClassifier(random_state=42)
tree.fit(X_train, y_train)
# 초기 정확도 측정
train_acc = tree.score(X_train, y_train)
test_acc = tree.score(X_test, y_test)
print(f"Before pruning - Train Accuracy: {train_acc:.4f}, Test Accuracy: {test_acc:.4f}")- 트리의 리프 노드를 하나씩 제거하면서 검증 데이터 성능을 평가하고 가지치기를 수행한다.
- 성능이 좋아지면 가지치기한 상태로 계속
- 성능이 나빠지면 원래대로(분기했던 상태로) 복구
from sklearn.tree import _tree
def prune_tree(tree, X_val, y_val):
"""
REP 방식으로 가지치기 수행: 리프 노드를 제거하며 검증 데이터 성능을 확인
"""
def prune_index(node):
""" 현재 노드가 리프 노드인지 확인 """
return (tree.tree_.children_left[node] == _tree.TREE_LEAF and
tree.tree_.children_right[node] == _tree.TREE_LEAF)
nodes_to_prune = np.where([prune_index(i) for i in range(tree.tree_.node_count)])[0]
for node in nodes_to_prune:
# 가지치기 시뮬레이션 (노드를 리프 노드로 변경)
left_child = tree.tree_.children_left[node]
right_child = tree.tree_.children_right[node]
if left_child == _tree.TREE_LEAF and right_child == _tree.TREE_LEAF:
original_left = tree.tree_.children_left[node]
original_right = tree.tree_.children_right[node]
# 노드를 리프 노드로 변경
tree.tree_.children_left[node] = _tree.TREE_LEAF
tree.tree_.children_right[node] = _tree.TREE_LEAF
# 가지치기 후 성능 확인
new_acc = tree.score(X_val, y_val)
if new_acc < test_acc: # 성능이 나빠지면 원상 복구
tree.tree_.children_left[node] = original_left
tree.tree_.children_right[node] = original_right
# 가지치기 실행
prune_tree(tree, X_test, y_test)
# 가지치기 후 정확도 확인
train_acc_after = tree.score(X_train, y_train)
test_acc_after = tree.score(X_test, y_test)
print(f"After pruning - Train Accuracy: {train_acc_after:.4f}, Test Accuracy: {test_acc_after:.4f}")
3.2. CCP
- 먼저 트리를 완전 성장시킨 후, `cost_complexity_pruning_path()`를 사용해 CCP에 사용될 α값 후보를 추출함.
- DecisionTreeClassifier의 `ccp_alpha` 매개변수에 α값 후보들을 넣고 훈련시키면 됨.
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 데이터 로드 및 분할
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# 트리 학습 (가지치기 없이 완전 성장)
tree = DecisionTreeClassifier(random_state=42)
tree.fit(X_train, y_train)
# CCP(비용 복잡도) 값 찾기
path = tree.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas, impurities = path.ccp_alphas, path.impurities
# 다양한 α 값에 대해 가지치기 후 성능 확인
trees = []
for ccp_alpha in ccp_alphas:
pruned_tree = DecisionTreeClassifier(random_state=42, ccp_alpha=ccp_alpha)
pruned_tree.fit(X_train, y_train)
trees.append(pruned_tree)
# 트리의 깊이 변화에 따른 alpha값 시각화
depths = [tree.get_depth() for tree in trees]
plt.plot(ccp_alphas, depths, marker="o")
plt.xlabel("CCP Alpha")
plt.ylabel("Tree Depth")
plt.title("Effect of CCP on Tree Depth")
plt.show()
3.3. Pre-pruning (by 하이퍼파라미터)
- 가지치기 없이 학습한 모델(tree_no_pruning)과 가지치기 수행한 모델(tree_with_pruning)의 성능을 비교해봄
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 1. 데이터 불러오기 (Iris 데이터셋 활용)
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.3, random_state=42)
# 2. 가지치기 없는 트리 모델
tree_no_pruning = DecisionTreeClassifier(random_state=42) # 기본 트리 (사전 가지치기 X)
tree_no_pruning.fit(X_train, y_train)
# 3. 가지치기 적용한 트리 모델
tree_with_pruning = DecisionTreeClassifier(max_depth=3, min_samples_split=10, min_samples_leaf=5, random_state=42)
tree_with_pruning.fit(X_train, y_train)
# 4. 모델 성능 비교
print(f"Before pruning - Train Accuracy: {tree_no_pruning.score(X_train, y_train):.4f}, Test Accuracy: {tree_no_pruning.score(X_test, y_test):.4f}")
print(f"After pruning - Train Accuracy: {tree_with_pruning.score(X_train, y_train):.4f}, Test Accuracy: {tree_with_pruning.score(X_test, y_test):.4f}")- 가지치기 전후 트리 모습을 시각화 해봄.
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
# 1. 가지치기 없이 학습된 트리 시각화
plot_tree(tree_no_pruning, feature_names=data.feature_names, class_names=data.target_names, filled=True, ax=ax[0])
ax[0].set_title("Before Pruning (Full Tree)")
# 2. 가지치기 적용된 트리 시각화
plot_tree(tree_with_pruning, feature_names=data.feature_names, class_names=data.target_names, filled=True, ax=ax[1])
ax[1].set_title("After Pre-Pruning (Restricted Tree)")
plt.show()
하지만 단일 트리 알고리즘은 가지치기(Pruning)로도 Overfitting의 문제를 완전히 극복할 수는 없습니다. Overfitting 없이 성능을 높이기에는 한계가 있죠. 따라서 단일 트리들을 모아 강력한 모델을 만드는 Ensemble method를 사용하게 되는데, 이는 다음 스터디에서 살펴보겠습니다!
🙏References
1) 사후 가지치기
- https://zephyrus1111.tistory.com/131#c2
- https://youtu.be/UFbJprjfS1E?si=Ii7_-5MGZzhocevh (강필성 교수님 Business Analytics 강의)
- https://youtu.be/my3ljAS5UUM?si=UvDVlweThmYuNSmZ
- https://velog.io/@emseoyk/%ED%95%B8%EC%A6%88%EC%98%A8-ML-with-Kaggle-6.-Decision-Tree-Pruning
2) 사전 가지치기
- 권철민(2022), 『파이썬 머신러닝 완벽 가이드』, 위키북스,
'ML & DL > 데이터마이닝' 카테고리의 다른 글
| [데이터마이닝] 클러스터링 알고리즘 (0) | 2025.03.06 |
|---|---|
| [데이터마이닝] 앙상블 학습 (Ensemble learning) (0) | 2025.03.05 |
| [데이터마이닝] 의사 결정 나무(Decision Tree) (2) | 2025.03.03 |
| [데이터마이닝] 하이퍼파라미터 튜닝 (Grid search, Random search, Bayesian optimization) (0) | 2025.03.02 |
| [데이터마이닝] 지도학습의 기본 원리 (MSE Decomposition, Variance-Bias Trade off) (0) | 2025.03.01 |