
👉방대한 데이터에서 필요한 부분만 선택하여 쓸 수 있다.
여기서부터는 데이터 분석 시 정말 자주 사용할 기능들이니 잘 배워두자.
- 데이터 준비 (이전과 동일)

Column 선택 (by 컬럼명)
- Column 이름(label)으로 호출하는 건 앞에서 했었음.

Column 선택 (by index)
- 데이터가 방대해지면 Column 명을 모두 알고 있을 수 없음 ㅠㅠ
⇒ 몇 번째 Column인지(정수 index)를 통해 호출해야 하는 경우가 더 많을 거임.

- 위처럼 .columns로 label을 불러오고, 거기다가 다시 인덱싱해서 Column을 호출!

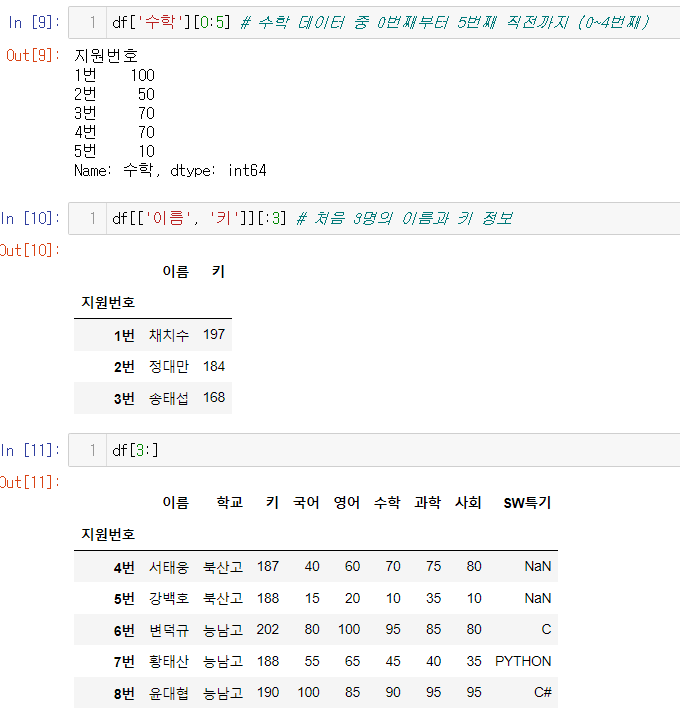
슬라이싱
- 범위를 적은 리스트 `[ ]`를 뒤에 이어붙이면 해당 부분만 잘라서 가져올 수 있음.
🧐My Point
❗여러 개를 한 번에 호출하고 싶을 땐 이중으로 리스트 씌우는 거 기억하자!
❗슬라이싱은 호출하는 리스트 내에서 설정하는 게 아니라 뒤에 추가로 갖다붙이는 느낌!

*본 포스팅은 이전에 Velog(https://velog.io/@simon919)에서 작성했던 글을 Tistory로 옮긴 것입니다.
'Python > Pandas' 카테고리의 다른 글
| [Pandas 기초] 8. 데이터 선택 (iloc) (0) | 2025.02.05 |
|---|---|
| [Pandas 기초] 7. 데이터 선택 (loc) (0) | 2025.02.05 |
| [Pandas 기초] 5. 데이터 확인 (0) | 2025.02.04 |
| [Pandas 기초] 4. 파일 저장 및 열기 (0) | 2025.02.03 |
| [Pandas 기초] 3. Index (0) | 2025.02.02 |