

SQL 쿼리 연습을 위해 다양한 문제를 풀어보고 있다.
다만, 대부분의 코딩테스트 플랫폼에서는 BigQuery 선택지가 없어서 MySQL 기준으로 연습하는 중이다.
(대부분의 문법이 비슷하지만 간혹 문법이나 정책이 다른 경우가 있는 듯하다)
아래와 같은 문제들을 기록해두고 복기하려고 한다.
- 어려워서 풀이에 실패한 문제
- 풀긴 했으나 좀 더 좋은 쿼리가 있었던 문제
- 몰랐던 문법이나 함수를 알게 된 문제
- 그 외 복기가 필요하다고 느낀 문제
1. Placements (해커랭크)
📌문제
- Write a query to output the names of those students whose best friends got offered a higher salary than them.
- Names must be ordered by the salary amount offered to the best friends. It is guaranteed that no two students got same salary offer.

📌풀이
- packages 테이블을 서로 다른 Key로 2번 조인하는 게 핵심!
/*
출력 컬럼: name
테이블:
- Students, Friends(베프), Packages
- salary 같은 학생은 없음을 전제
조건:
- 베프가 자기보다 높은 salary인 경우를 뽑아라.
- 베프의 salary 기준으로 정렬
*/
-- 1) 내id, 친구id, 내salary, 친구salary 출력해봄
SELECT
F.id,
F.friend_id,
My_S.salary as my_salary,
Fr_S.salary as friend_salary
FROM friends as F
LEFT JOIN packages as My_S ON F.id=My_S.id -- 내salary
LEFT JOIN packages as Fr_S ON F.friend_id=Fr_S.id -- 친구salary
-- 2) 친구 salary가 더 높은 경우로 조건 추가
SELECT
F.id,
F.friend_id,
My_S.salary as my_salary,
Fr_S.salary as friend_salary
FROM friends as F
LEFT JOIN packages as My_S ON F.id=My_S.id
LEFT JOIN packages as Fr_S ON F.friend_id=Fr_S.id
WHERE My_S.salary <= Fr_S.salary
-- 3) students 테이블 연결해서 name도 추가로 출력
SELECT
F.id,
S.name, -- 추가
F.friend_id,
My_S.salary as my_salary,
Fr_S.salary as friend_salary
FROM friends as F
LEFT JOIN packages as My_S ON F.id=My_S.id
LEFT JOIN packages as Fr_S ON F.friend_id=Fr_S.id
LEFT JOIN students as S ON F.id=S.id -- 추가
WHERE My_S.salary <= Fr_S.salary
-- 4) 정렬 추가 & 불필요한 컬럼들 지워주면 최종 답안
SELECT
S.name
FROM friends as F
LEFT JOIN packages as My_S ON F.id=My_S.id
LEFT JOIN packages as Fr_S ON F.friend_id=Fr_S.id
LEFT JOIN students as S ON F.id=S.id
WHERE My_S.salary <= Fr_S.salary
ORDER BY Fr_S.salary💡배운 점
단계별 풀이 과정을 기억하고자 기록함
2. Binary Tree Nodes (해커랭크)
📌문제
- You are given a table, 'BST': column 'N' represents the value of a node in Binary Tree, and 'P' is the parent of N
- Write a query to find the node type of Binary Tree ordered by the value of the node. Output one of the following for each node:
- Root: If node is root node.
- Leaf: If node is leaf node.
- Inner: If node is neither root nor leaf node.

📌풀이
- 각 노드타입의 특징을 파악하고, 이를 조건으로 구현
- Root: 부모가 없음 = P가 Null임
- Leaf: 자식이 없음 = P컬럼에 등장하지 않음 (누군가의 부모가 아니기 때문)
- Inner: 그 외
/*
출력 결과: 노드의 타입(Root, Leaf, Inner 중 하나)
테이블:
- BST(N=노드 번호, P는 N의 부모 번호)
조건:
- Root = P IS NULL
- Leaf = NOT IN P
- Inner = 그 외 나머지
*/
-- 1) 일단 루트 조건만 넣고 출력해봄 = 15가 루트노드구나
SELECT
N,
P,
CASE
WHEN(bst.P IS NULL) THEN "Root"
ELSE "not Root"
END as node_type
FROM bst
-- 2) NOT IN P로 실행했으나 오류 발생⚠️
SELECT
N,
P,
CASE
WHEN(P IS NULL) THEN "Root"
WHEN(N NOT IN P) THEN "Leaf"
ELSE "Inner"
END as node_type
FROM bst
-- 3) 서브쿼리로 바꾸고, 필요한 컬럼만 출력 & 정렬
SELECT
N,
CASE
WHEN(P IS NULL) THEN "Root"
WHEN(N NOT IN (SELECT P FROM bst WHERE P IS NOT NULL)) THEN "Leaf"
ELSE "Inner"
END as node_type
FROM bst
ORDER BY N
-- (⭐추가 풀이) 셀프 조인으로도 풀 수 있음
SELECT
DISTINCT(t1.N), -- DISTINCT 해줘야 함!
CASE
WHEN(t1.P IS NULL) THEN "Root"
WHEN(t2.P IS NULL) THEN "Leaf" -- t2.N으로 해도 됨
ELSE "Inner"
END as node_type
FROM bst as t1
LEFT JOIN bst as t2
ON t1.N = t2.P -- 이러면 P열에 없는 노드는 t2.P가 NULL이 됨!
ORDER BY t1.N💡배운 점
- 1) IN은 괄호에 값 목록 or 서브쿼리를 기대함
- 그래서 NOT IN P처럼 컬럼을 직접적으로 입력하면 오류 발생했던 것..!
3. Top Earners (해커랭크)
📌문제
- We define an employee's total earnings to be their monthly `salary * months` worked, and the maximum total earnings to be the maximum total earnings for any employee in the Employee table.
- Write a query to find the maximum total earnings for all employees as well as the total number of employees who have maximum total earnings. Print these values as 2 space-separated integers.

📌풀이
- 풀이1) 서브쿼리 없이 SELECT에서 바로 연산
SELECT
salary*months as total_earnings,
COUNT(employee_id) as cnt_employee
FROM employee
GROUP BY total_earnings
ORDER BY total_earnings DESC
LIMIT 1- 풀이2) FROM절 서브쿼리
SELECT
total_earnings,
COUNT(employee_id) as cnt_employee -- (3) 개수 계산하고
FROM(
SELECT
*,
salary*months as total_earnings -- (1) 이 컬럼 추가한 테이블을 따로 만들고
FROM employee
) as employee2
GROUP BY total_earnings -- (2) 거기서 그룹화 해서
ORDER BY total_earnings DESC -- (4) 정렬 후 출력
LIMIT 1- 풀이3) WHERE절 서브쿼리 (HAVING도 가능)
SELECT
salary*months AS earnings,
COUNT(employee_id)
FROM employee
WHERE salary*months = (SELECT MAX(salary*months) FROM employee)
GROUP BY earnings
-- ➕그룹화 먼저 하고, HAVING에 조건 걸어도 됨!
SELECT
salary*months AS earnings,
COUNT(employee_id)
FROM employee
GROUP BY earnings
HAVING earnings = (SELECT MAX(salary*months) FROM employee) -- 서브쿼리 조건은 동일함💡배운 점
- 1) FROM절 말고 다른 곳에서도 자유롭게 서브쿼리를 활용할 수 있음! = SELECT, WHERE, HAVING 등
4. Department Highest Salary (리트코드 184번)
📌문제
- Write a solution to find employees who have the highest salary in each of the departments. Return the result table in any order.
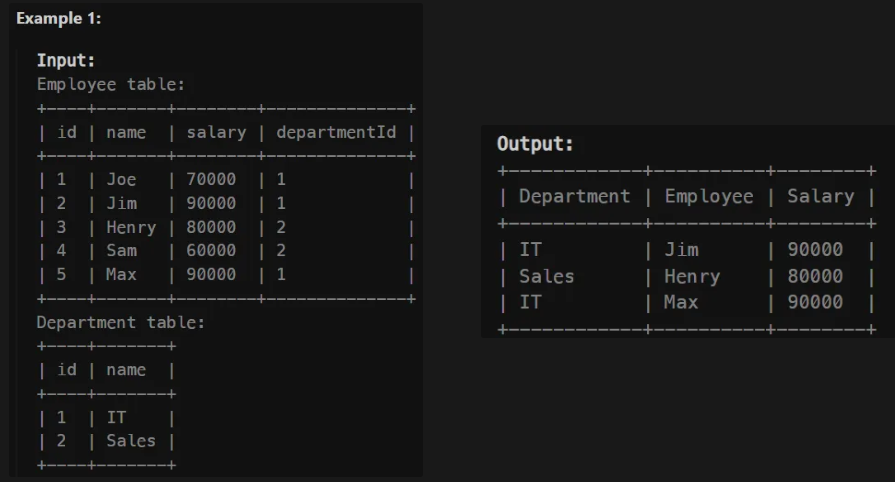
📌풀이
- 풀이1) WHERE절 서브쿼리 활용
- 바깥 WHERE절의 조건을 각 행에 맞게 적용시키는 WHERE departmentId = e.departmentId가 핵심!!⭐
- ex) 첫 행의 `departmentId = 2` 라면, 서브쿼리 내 WHERE절은 `WHERE departmentId = 2` 로 인식되는 것!
-- 1) 일단 부서명 빼고 출력
SELECT
name,
salary
FROM employee as e -- ① e 테이블의 첫 행부터 쭉 검사 시작
WHERE salary = ( -- ② WHERE 조건에 맞는 행인지 보기 위해 서브쿼리 들어감
SELECT MAX(salary)
FROM employee -- ③바깥 e와 별도로 다시 employee 테이블 정의하고
WHERE departmentId = e.departmentId --⭐④지금 검사 중이던 행의 departmentId를 참조해서 WHERE 조건을 만듦
) -- ⑤그럼 이 서브쿼리는 즉, e 테이블에서 지금 검사 중인 행의 부서에서 MAX인 salary값을 찾아주는 역할을 함
-- 2) 조인으로 부서명도 같이 출력
SELECT
d.name AS Department,
e.name AS Employee,
salary AS Salary -- 별칭도 형식에 맞게 추가
FROM employee as e
JOIN department as d ON e.departmentId = d.id
WHERE salary = (SELECT MAX(salary)
FROM employee
WHERE departmentId = e.departmentId)- 풀이2) FROM절 서브쿼리 활용 (by. GPT 도움)
- INNER JOIN 조건으로 salary가 max인 경우만 필터링한 게 핵심!⭐
-- 1) 테이블 구조 이해를 위해 부서별 최대 salary 출력해봄
SELECT
departmentId,
MAX(salary)
FROM employee AS e
GROUP BY departmentId
/* 출력 결과
| departmentId | MAX(salary) |
| ------------ | ----------- |
| 1 | 90000 |
| 2 | 80000 |
*/
-- 2) 1의 결과를 임시테이블로 만들고 조인
SELECT
d.name AS Department,
e.name AS Employee,
e.salary AS Salary
FROM employee AS e
INNER JOIN ( -- 최대 salary 정보만 있는 임시테이블을 조인
SELECT departmentId, MAX(salary) AS max_salary
FROM employee
GROUP BY departmentId
) AS ms
ON e.departmentId = ms.departmentId AND e.salary = ms.max_salary --⭐조인을 통해 부서별 max salary인 행만 남김!
INNER JOIN department AS d -- 부서명 출력을 위해 추가로 조인
ON e.departmentId = d.id💡배운 점
- 1) WHERE절의 조건을 각 행에 맞게 적용시킬 때 서브쿼리를 어떤 식으로 쓰면 되는지 알게 됨!
- ex. 그 직원이 속한 부서의 평균 급여, 최대 급여 등을 구할 때 유용함
- 바깥 FROM절 테이블을 별칭 지정 & WHERE절 서브쿼리 내에서 그걸 참조 ➡️각 행마다 WHERE 조건 적용 가능!!
- 2) JOIN에서도 서브쿼리로 만든 테이블을 사용할 수 있음!
5. Challenges (해커랭크)
📌문제
- Julia asked her students to create some coding challenges. Write a query to print the hacker_id, name, and the total number of challenges created by each student. Sort your results by the total number of challenges in descending order. If more than one student created the same number of challenges, then sort the result by hacker_id.
- If more than one student created the same number of challenges and the count is less than the maximum number of challenges created, then exclude those students from the result.

📌풀이
- 풀이1) WITH문 사용, JOIN은 나중에
- WHERE 조건 내에서 서브쿼리 사용: cnt_ch가 최대이거나, cnt_ch가 중복되지 않은 경우만 필터링
/*
출력: hacker_id, name, 각 학생이 만든 challenge 개수 (단, 동점자는 개수가 최대일 때만 출력)
정렬: 각 학생이 만든 challenge 개수(내림차순), hacker_id
*/
-- 1) 일단 hacker_id별 challenge 개수 출력해봄
SELECT
hacker_id,
COUNT(challenge_id) AS cnt_ch
FROM challenges
GROUP BY hacker_id
ORDER BY cnt_ch DESC
-- 2) challenge 개수마다 hacker_id 개수를 세어봄 = 2개 이상인 건 다 동점자
SELECT
cnt_ch,
COUNT(hacker_id) AS cnt_hacker
FROM(
SELECT
hacker_id,
COUNT(challenge_id) AS cnt_ch
FROM challenges
GROUP BY hacker_id
) AS cnt
GROUP BY cnt_ch
HAVING cnt_hacker > 1
ORDER BY cnt_hacker DESC
-- 3) 그냥 1의 결과를 with문 써서 별도 테이블 temp로 만들자
WITH temp AS(
SELECT
hacker_id,
COUNT(challenge_id) as cnt_ch
FROM challenges
group by hacker_id
)
SELECT
hacker_id,
cnt_ch
FROM temp
-- ⭐WHERE 조건을 2개로 쪼개서 해결함!
WHERE (cnt_ch = (SELECT MAX(cnt_ch) FROM temp)) -- cnt_ch가 최대이거나,
OR (cnt_ch IN ( -- cnt_ch가 중복되지 않은 경우만 필터링
SELECT cnt_ch
FROM temp
GROUP BY cnt_ch
HAVING COUNT(hacker_id)<2)
)
ORDER BY cnt_ch DESC, hacker_id -- 그리고 정렬해보니 잘 나옴!
-- 4) 제출을 위해 hacker 이름만 추가로 출력하면 끝✅
WITH temp AS(
SELECT
hacker_id,
COUNT(challenge_id) as cnt_ch
FROM challenges
group by hacker_id
)
SELECT
t.hacker_id,
h.name, -- 여기만 추가됨
t.cnt_ch
FROM temp as t
JOIN hackers as h ON t.hacker_id = h.hacker_id -- 여기만 추가됨
WHERE (cnt_ch = (SELECT MAX(cnt_ch) FROM temp))
OR (cnt_ch IN (
SELECT cnt_ch
FROM temp
GROUP BY cnt_ch
HAVING COUNT(hacker_id)<2)
)
ORDER BY cnt_ch DESC, hacker_id- 👨🏻🏫풀이2) WITH문 사용, JOIN도 미리 해버림
WITH challenge_counts AS (
SELECT
h.hacker_id,
h.name, -- 아예 name까지 합쳐서 WITH 테이블로 만듦
COUNT(challenge_id) AS cnt_ch
FROM challenges AS c
JOIN hackers AS h ON c.hacker_id = h.hacker_id -- 풀이1)과 달리 조인을 여기서 미리 함
GROUP BY 1,2
)
SELECT
hacker_id,
name,
cnt_ch
FROM challenge_counts
WHERE cnt_ch IN (SELECT cnt_ch
FROM challenge_counts
GROUP BY cnt_ch
HAVING COUNT(*) = 1) -- 중복이 아니라는 조건을 이렇게 써도 됨
OR cnt_ch = (SELECT MAX(cnt_ch) FROM challenge_counts)
ORDER BY cnt_ch DESC, hacker_id- 👨🏻🏫풀이3) 서브쿼리를 중첩으로 사용
- 풀이1의 temp 테이블을 그냥 서브쿼리로 매번 직접 적은 셈
SELECT
c.hacker_id,
h.name,
COUNT(challenge_id) as cnt_ch --⭐집계 컬럼을 SELECT에서 바로 사용한 대신,
FROM challenges as c
JOIN hackers as h ON c.hacker_id = h.hacker_id
GROUP BY 1,2
--⭐조건을 HAVING절로 설정 (WHERE절 사용한 풀이1과 달리)
HAVING (cnt_ch = (SELECT MAX(cnt_ch)
FROM( -- 이 부분이 temp 테이블과 동일!
SELECT hacker_id, COUNT(challenge_id) as cnt_ch
FROM challenges
GROUP BY hacker_id) as sub)
)
OR (cnt_ch IN (SELECT cnt_ch
FROM( -- 이 부분이 temp 테이블과 동일!
SELECT hacker_id, COUNT(challenge_id) as cnt_ch
FROM challenges
GROUP BY hacker_id) as sub
GROUP BY cnt_ch
HAVING COUNT(hacker_id)<2)
)
ORDER BY cnt_ch DESC, hacker_id💡배운 점
- 1) 서브쿼리 쓰기 복잡할 때는 WITH문으로 테이블 만들어버리는 게 나을 수 있다!
- 이 문제도 서브쿼리 쓴 풀이3은 매우 복잡해진 것을 볼 수 있음 ㅠ
- 2) 출력 조건이 복잡해보일 때는 여러 개로 쪼갤 수 없는지 생각해보자!
- 이 문제에서도 WHERE 조건을 2개로 쪼개고 OR로 연결했음
- 3) 집계 컬럼은 무작정 별도 테이블로 만들기 전에, HAVING절로 바로 해결할 순 없는지 확인하자!
- 풀이3에서 cnt_ch를 굳이 별도 테이블로 안 만들고, SELECT에서 집계 후 HAVING절로 조건 걸었음 (맨 안쪽 서브쿼리만 with문으로 바꾸면 풀이1, 풀이2만큼 충분히 간결한 쿼리가 되네)
💡배운 점 모아두기
- IN은 괄호에 값 목록 or 서브쿼리를 기대함 → 컬럼명 그대로 넣으면 안 됨
- FROM절 외에도 자유롭게 서브쿼리를 활용할 수 있음! = SELECT, WHERE, HAVING, JOIN 등
- WHERE절에 서브쿼리를 쓰면 WHERE 조건을 각 행에 맞게 적용시킬 수 있음!! (4번 문제 참고)
- 서브쿼리 쓰기 복잡할 때는 WITH문으로 별도 테이블 만드는 게 나을 수 있음
- 출력 조건이 복잡해보일 때는 여러 개로 쪼갤 수 없는지 생각해보자 (+AND, OR 사용)
- 집계 컬럼은 무작정 별도 테이블로 만들기 전에, HAVING절로 바로 해결할 순 없는지 확인하자
'SQL > MySQL' 카테고리의 다른 글
| [MySQL] Window 함수 (0) | 2025.05.01 |
|---|---|
| [MySQL] UNION, 서브쿼리 (0) | 2025.04.29 |
| [MySQL] Data Manipulation Language (INSERT, UPDATE, DELETE) (0) | 2025.04.27 |
| [MySQL] 해커랭크 문제 풀이 (3) (1) | 2025.04.24 |
| [MySQL] 해커랭크, 리트코드 문제 풀이 (2) (0) | 2025.03.24 |