
1. JOIN 개념 이해
- 간단히 말해, 서로 다른 데이터(테이블)를 연결하는 작업
- 처음에 좀 어렵게 느껴질 수 있는데, 문제 많이 풀어보면서 체화하는 게 좋음!
- 연결하려는 테이블들에 공통으로 존재하는 컬럼(=Key)이 있어야 JOIN 가능!
- 보통 id 값을 많이 사용하고, 특정 범위(ex. Date)로도 JOIN 가능함
포켓몬 데이터 예시
ex) 트레이너 데이터(trainer)와 포켓몬 데이터(pokemon)를 연결해보고 싶다면?
- 두 데이터를 연결할 수 있는 공통값(key)이 없어서 불가능함.
- (id가 있다고 생각할 수 있지만, 엄밀하게는 각각 trainer_id, pokemon_id로 다른 값이라서 안 됨. 바로 연결하려면 trainer 테이블에 pokemon_id와 같은 컬럼이 있어야 함 → 그래서 보통 연결할 수 있는 테이블인지 파악할 때 xxx_id, xxx_name 같은 컬럼이 있나 확인함)

- 트레이너가 포획한 포켓몬 데이터(trainer_pokemon) 를 사용하면 연결 가능함! (trainer_id를 trainer 테이블의 id와 연결, pokemon_id를 pokemon 테이블의 id와 연결)
- ➔ 이러면 이제 단일 자료로는 할 수 없던 분석이 가능해짐 (ex. 트레이너는 선호하는 포켓몬 타입대로 실제 포켓몬을 잡을까?)
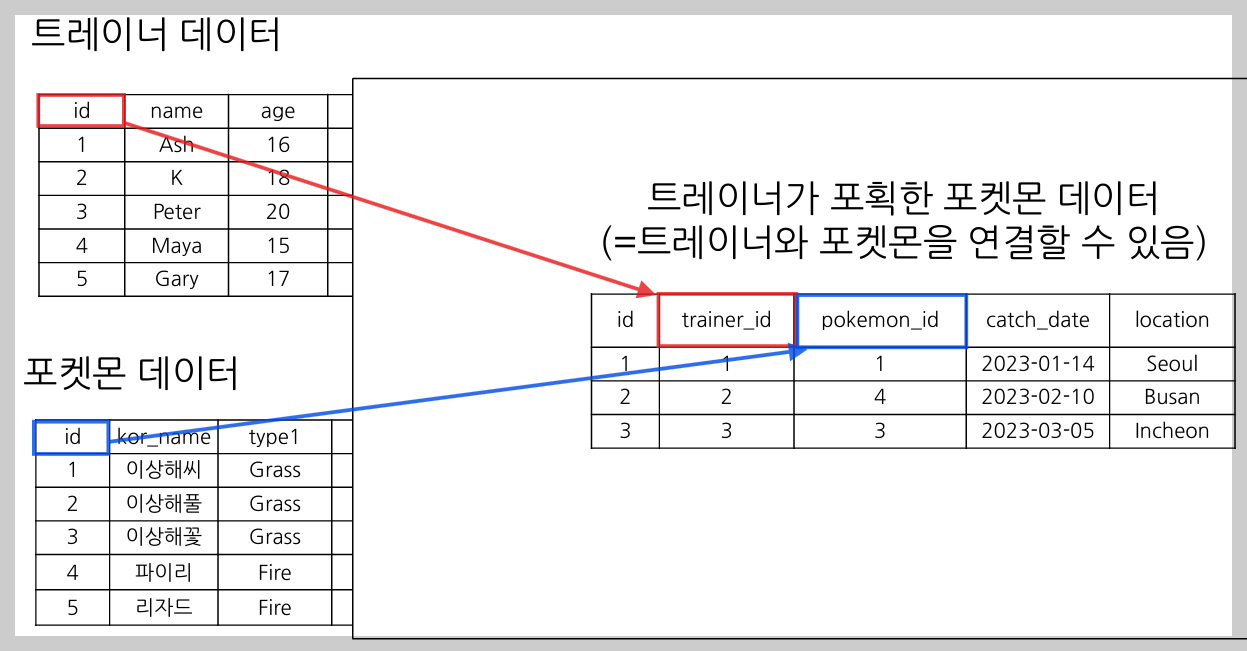
- 만약 (기준 테이블이 trainer_pokemon이라는 가정 하에) trainer_id와 id를 연결(JOIN)할 경우, trainer_pokemon의 우측에 trainer 테이블의 정보들이 추가됨 (=trainer 테이블의 컬럼들이 옆에 추가됨)
- 이때 trainer_id, id가 JOIN Key라고 보면 됨

JOIN이 필요한 이유
👨🏫왜 굳이 여러 테이블을 놔두고 JOIN으로 연결해서 사용할까? 그냥 한 번에 다 저장하면 안 되는 걸까?
➔ 데이터가 저장되는 형태를 이해하면 답이 나옴.
- 관계형 데이터베이스(RDBMS) 설계 시 정규화 과정을 거침.
- 정규화란 중복을 최소화하도록 데이터를 구조화하는 것
- ex) User 테이블에는 사용자 관련 정보만, Order 테이블에는 주문 관련 정보만
- 그런데 모든 정보(컬럼)을 한 번에 저장하면 중복이 엄청 많이 발생하게 됨!
그래서 다양한 테이블에 나눠서 저장해두고, 필요할 때 연결(JOIN)해서 사용하는 것이 개발 관점에서 더 좋음 ! - 최근에는 데이터 웨어하우스에서 JOIN + 필요한 가공을 해서 다시 저장해두는 방식을 많이 사용함
- = "데이터 마트"
- 가장 기본적인 데이터 마트 예시: Order 테이블 → 일자별, 주문타입별, 지역별, 주문 건수, 매출
2. 다양한 JOIN 함수
- JOIN을 수행하는 여러 방법이 있음
- 처음에 어렵다면 LEFT JOIN만 주로 사용해도 충분함! (여기서 조건 걸면 INNER JOIN도 가능)
INNER JOIN : 두 테이블의 공통 요소만 연결

LEFT JOIN : 왼쪽 테이블 기준으로 연결 (왼쪽 테이블 그대로 두고, 오른쪽 중에 겹치는 행만 결합)

RIGHT JOIN : 오른쪽 테이블 기준으로 연결 (오른쪽 테이블 그대로 두고 , 왼쪽 중에 겹치는 행만 결합)

FULL JOIN : 양쪽 기준으로 모두 연결 (KEY 전부 가져오고, 왼/오 전부 결합)

CROSS JOIN : 두 테이블 각각의 요소를 곱함 (각 행끼리 모든 조합을 생성하며 결합)
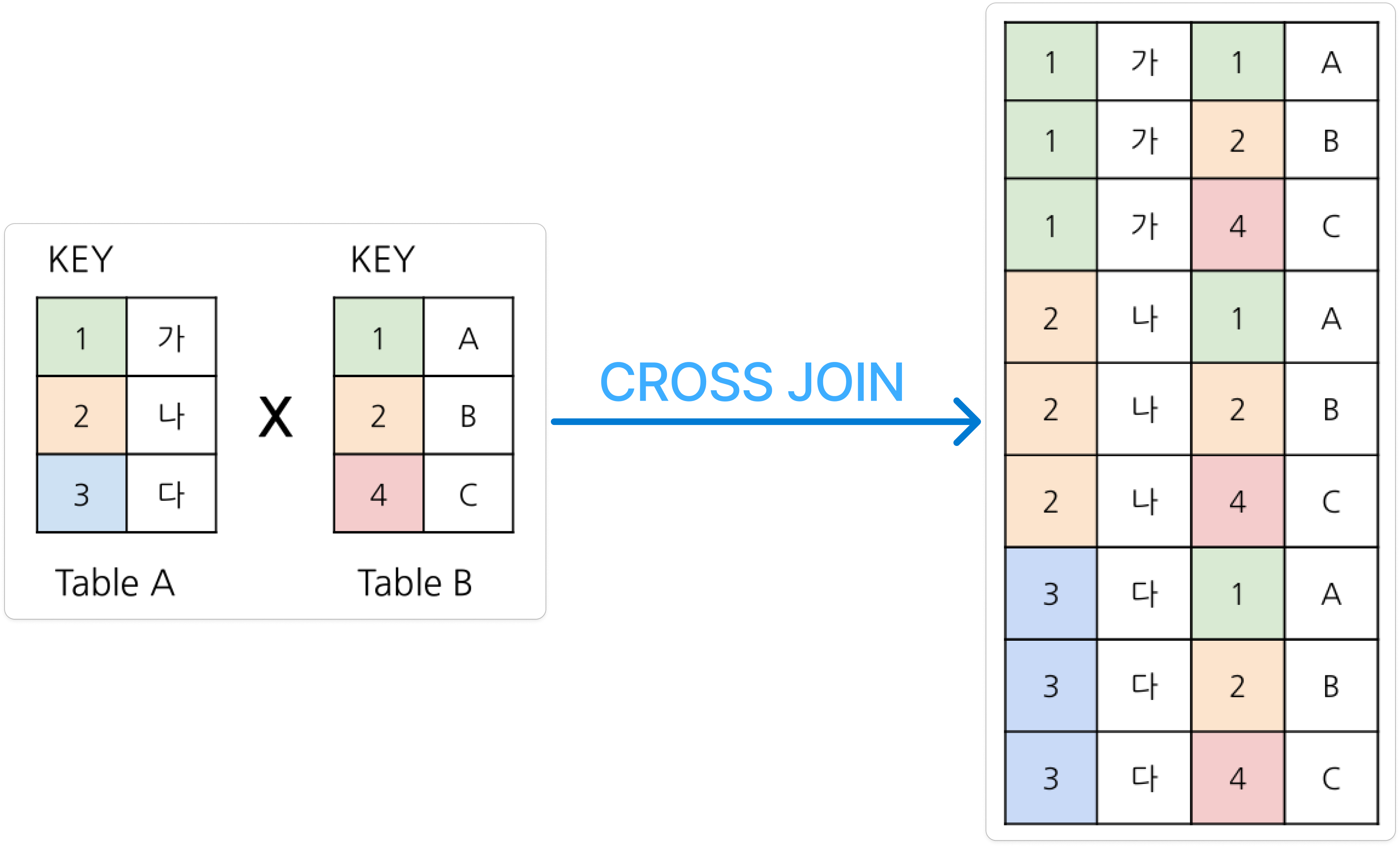
👨🏫판단하기 헷갈릴 때는 벤다이어그램으로 그려서 생각해보는 걸 추천!
ex) A 테이블과 B 테이블 교집합인 데이터도 필요하고, A에만 있는 것도 필요해 => LEFT JOIN 사용!

3. JOIN 쿼리 작성 방법
작성 흐름
- 테이블 확인 : 테이블에 저장된 데이터 특징, 컬럼 확인
- 기준 테이블 정의 : 가장 많이 참고할 테이블을 정의 (ex. LEFT JOIN일 경우, left로 어떤 테이블을 쓸 것인지)
= Row 개수가 적으면서 내가 원하는 정보를 최대한 포함하는 테이블 - JOIN Key 찾기 : 여러 테이블과 연결할 Key 정리 (`ON` 위치에 작성함)
- 결과 예상하기 : 결과 테이블을 예상해서 손/엑셀로 작성해보기 (=정답지 역할. 익숙해지면 생략 가능)
- 쿼리 작성 및 검증 : 쿼리를 실행하고, 예상했던 결과와 동일한 결과가 나왔는지 확인
쿼리 문법
- `FROM` 하단에 `JOIN`할 테이블을 작성하고, `ON` 뒤에 공통 컬럼(Key)을 작성
- 테이블 이름 길면 별칭(Alias) 자주 사용함!
- ⚠️CROSS JOIN은 Key 없어도 연산이 돼서 `ON` 필요 없음!
- INNER, LEFT, RIGHT, FULL 다 동일하게 사용하는데, CROSS JOIN만 다름!
SELECT
A.col1,
A.col2,
B.col11,
B.col12
FROM table1 AS A
LEFT JOIN table2 AS B
ON A.key = B.key -- 별칭으로 간단히 입력- 그리고, JOIN은 연달아 수행할 수도 있음
- ex) trainer_pokemon 테이블에 trainer 테이블을 연결 & 거기다 다시 pokemon 테이블을 연결
- BigQuery 실습 과정은 더보기 참고
SELECT
tp.*,
t.* EXCEPT(id), -- 어차피 tp에 있으니 제외
p.* EXCEPT(id) -- 어차피 tp에 있으니 제외
FROM basic.trainer_pokemon AS tp
LEFT JOIN basic.trainer AS t
ON tp.trainer_id = t.id -- 여기까지 한 덩어리
LEFT JOIN basic.pokemon AS p -- 그리고 다시 JOIN 수행
ON tp.pokemon_id = p.id1) trainer_pokemon 테이블에 trainer 테이블을 연결

2) 이어서 pokemon 테이블을 추가로 연결

3) id 컬럼이 3번이나 중복되니까 EXCEPT로 제외해주기
헷갈릴 만한 부분
1. 여러 JOIN 중 어떤 것을 사용해야 할까?
- 하려는 작업 목적에 따라 다름.
- 교집합이 필요하면 INNER, 모든 조합이 필요하면 CROSS, 그게 아니면 LEFT/RIGHT
- 처음엔 하나를 계속 활용하는 걸 추천
(ex. LEFT 쓰다가 오른쪽에 붙은 테이블에 NULL 생기면, `WHERE col1 IS NOT NULL` 해서 INNER JOIN과 같은 결과를 얻을 수 있음!) - 👨🏫쿼리 작성 템플릿에 꼭 예상 결과를 쓰고, 중간 결과도 적어보면서 단계적으로 실행하는 연습하기!
2. 어떤 Table을 왼쪽에 두고, 어떤 Table을 오른쪽에 둬야 할까?
- LEFT JOIN은 기준이 되는 테이블을 왼쪽에 둠
- 기준 = '내가 필요한 데이터 요소가 빠짐없이 있는가'로 판단하기!
- ex1) 주문한 유저들의 정보가 필요한 경우 : order 테이블을 기준으로 두고 user 테이블을 붙이면, 애초에 주문한 유저들의 정보만 가져올 수 있음
- ex2) 주문 안 한 유저들을 확인하고 싶은 경우 : user 테이블을 기준으로 두고 order 테이블 붙이면, NULL값이 발생할 거임. 그럼 IS NULL 조건 걸어서 주문 안 한 정보들을 확인할 수 있음
- 왼쪽에 어떤 테이블을 두느냐에 따라 어떻게 달라지는지 예상 결과를 써보는 연습하자!
3. 여러 Table을 연결할 수 있는 걸까?
- JOIN 개수에 한계는 없지만, 너무 많이 하는 것도 좋지 않음 (3~5개까지가 적절하다고 하심)
- 여러 개 연결하는 경우 `WITH`를 활용하면 가독성 있게 쿼리 작성 가능 (나중에 배울 예정)
4. 컬럼은 모두 다 선택해야 할까?
- 역시 하려는 작업에 따라 달라짐.
- 처음엔 JOIN 잘 됐는지 보기 위해 많은 컬럼 select 해도 되지만, 사용하지 않을 컬럼을 계속 select하면 BigQuery 비용이 그만큼 부과됨.. (데이터 크면 1번 실행하는 데 몇 만원이 들 수도,,,)
5. NULL이 대체 뭘까?
- NULL = 값 자체가 없음. 알 수 없음. 🆚 0 또는 공백("")과 다름!!
- JOIN 시 연결할 값이 없으면 생기게 됨
4. 연습문제
문제 1. 트레이너가 보유한 포켓몬들은 각각 얼마나 있는지 알 수 있는 쿼리를 작성해주세요. 단, 포켓몬 이름이 명시되어야 합니다. (*보유했다의 정의는 status가 'Active', 'Training'인 경우를 의미 & 'Released'는 방출했다는 것을 의미)
▶내 풀이 과정
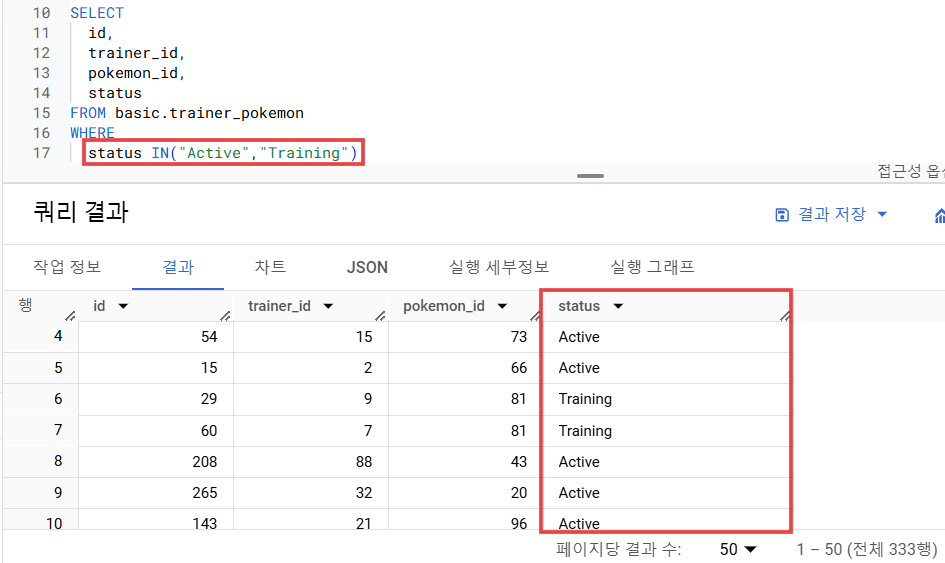
1) 데이터 확인
- 일단 status가 "Active" 또는 "Training"인 경우를 출력해봄
2) trainer_pokemon을 기준으로 두고 pokemon을 LEFT JOIN으로 연결
- 그리고 kor_name까지 같이 나오도록 출력해봄

2) 방금 출력한 걸 원본으로 하도록 서브쿼리로 감싸고, COUNT & GROUP BY 사용해서 집계!
- 일단 답은 맞는 듯?

▶강사님 풀이 과정✅
1) 데이터 확인
- 내 풀이와 동일하게 trainer_pokemon만 WHERE 걸어서 조회
2) tp 테이블 자체를 'WHERE 조건 걸어둔 테이블'로 줄여둔 뒤, LEFT JOIN으로 결합!

3) 조회 한 번 해서 확인한 뒤, 똑같이 COUNT & GROUP BY 사용해서 집계
- ⭐단, JOIN한 테이블에 중복된 컬럼(`id`)이 있을 때는 어떤 테이블인지 반드시 명시해줘야 함(`tp.id`)

👨🏫JOIN을 먼저 하는 게 좋을까, WHERE로 조건을 먼저 걸어두는 게 좋을까?
- 일단 row 수를 줄여두고 시작하는 게 연산량이 줄어듦! 그러니 WHERE을 먼저 쓰자! (단, 줄이고 써도 작업 목적에 문제가 없어야 함!) 🆚내가 짠 코드는 JOIN을 먼저 한 셈이네..
- 그리고 지금 쿼리가 좀 복잡하고 길어보일 텐데, 나중에 WITH로 가독성 높이는 법 배울 예정!
▶전체 코드
-- 쿼리 작성하는 목표, 확인할 지표 : Active OR Training인 포켓몬들의 개수
-- 쿼리 계산 방법 : count, left join
-- 데이터의 기간 :
-- 사용할 테이블 : pokemon, trainer_pokemon
-- JOIN KEY : id, pokemon_id
-- 데이터의 특징 :
-- 보유했다의 정의는 status가 'Active', 'Training'인 경우를 의미
SELECT
-- tp.*, 조회 한 번 해본 뒤
-- p.id,
-- p.kor_name,
kor_name,
COUNT(tp.id) AS pokemon_cnt
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status,
FROM basic.trainer_pokemon
WHERE
status IN("Active","Training")
)AS tp -- 이렇게 row 수를 먼저 줄여두기!⭐
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
GROUP BY kor_name
/* 내 풀이
SELECT
kor_name,
COUNT(id) AS pokemon_cnt
FROM(
SELECT
tp.id,
tp.trainer_id,
tp.pokemon_id,
tp.status,
p.kor_name
FROM basic.trainer_pokemon AS tp
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
WHERE
status IN("Active","Training")
)
GROUP BY kor_name
*/
문제 2. 트레이너가 보유한 포켓몬 중에서 'Grass' 타입은 몇 마리인지 계산해주세요 (단, 편의를 위해 type1 기준으로 계산해주세요)
▶내 풀이 과정✅
1) 데이터 확인
문제 1과 동일
2) WHERE 조건 걸어둔 trainer_pokemon을 기준으로 두고 pokemon을 LEFT JOIN으로 연결
- tp 전체와, p의 kor_name, type1 이 잘 출력되는지 확인 (이제 여기서 "Grass"의 개수를 세면 됨)
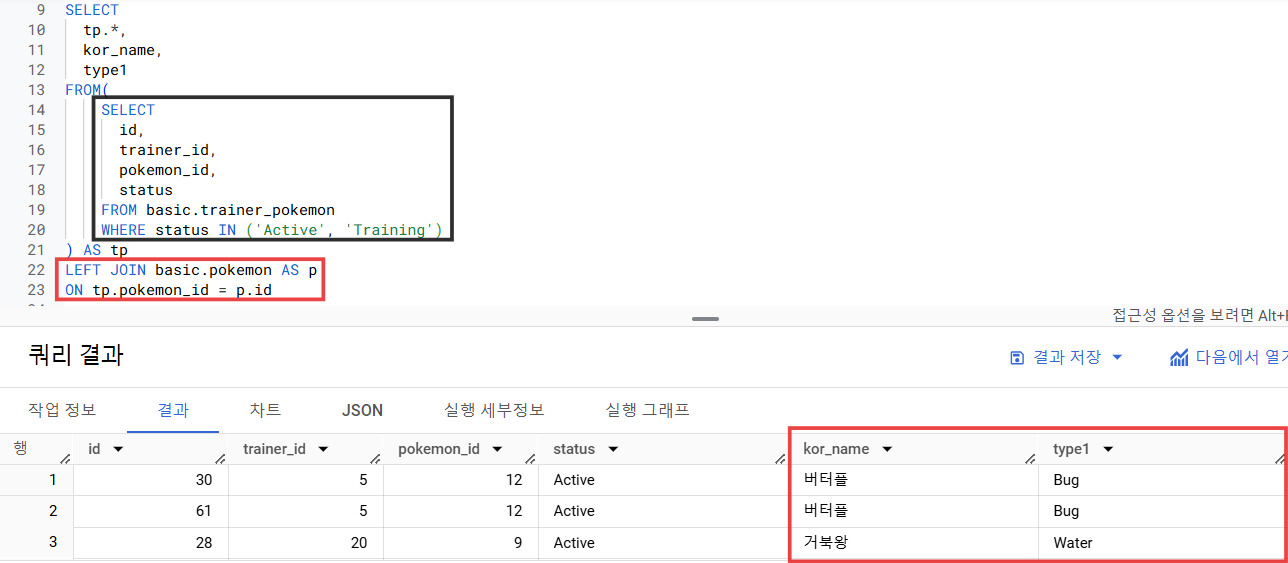
3) COUNT & GROUP BY로 type별 개수 출력 (나머지 select는 주석 처리)
- 그러면 Grass 타입이 23개임을 확인 가능!

▶강사님 풀이 과정✅
1) 내 풀이와 비슷한데, GROUP BY 전에 WHERE 조건을 걸어서 아예 Grass 타입 개수만 출력!
- 엄밀히 말하면 이렇게 출력하는 게 정답!
- +깨알 팁 : GROUP BY, ORDER BY 할 때 컬럼을 숫자로 지정할 수 있었음!

▶전체 코드
-- 쿼리 작성하는 목표, 확인할 지표 : 보유 중인 포켓몬 중 type1="Grass" 개수
-- 쿼리 계산 방법 : JOIN, Count + Groupby
-- 데이터의 기간 :
-- 사용할 테이블 : trainer_pokemon, pokemon
-- JOIN KEY : tp.pokemon_id = p.id
-- 데이터의 특징 : '보유'=status 컬럼으로 확인
SELECT
-- tp.*,
-- kor_name,
type1,
COUNT(tp.id) AS cnt
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status
FROM basic.trainer_pokemon
WHERE status IN ('Active', 'Training')
) AS tp
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
WHERE type1 = "Grass"
GROUP BY 1 -- type1 컬럼을 숫자로 지정해봄
/* 내 풀이 과정
SELECT
-- tp.*,
-- kor_name,
type1,
COUNT(tp.id) AS cnt
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status
FROM basic.trainer_pokemon
WHERE status IN ('Active', 'Training')
) AS tp
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
GROUP BY type1
*/
문제 3. 트레이너의 고향(hometown)과 포켓몬을 포획한 위치(location)를 비교하여, 자신의 고향에서 포켓몬을 포획한 트레이너의 수를 계산해주세요. (*status 상관없이 구해주세요)
▶내 풀이 과정❎
1) 데이터 확인
2) 일단 LEFT JOIN 걸어서, hometown과 location을 한 테이블에서 볼 수 있게 연결

3) WHERE 조건만 추가해서 다시 조회 (location = hometown)
- 이제 여기서 trainer_id의 개수를 세면 되겠다! (여기서 이미 행 개수 알 수 있긴 함)
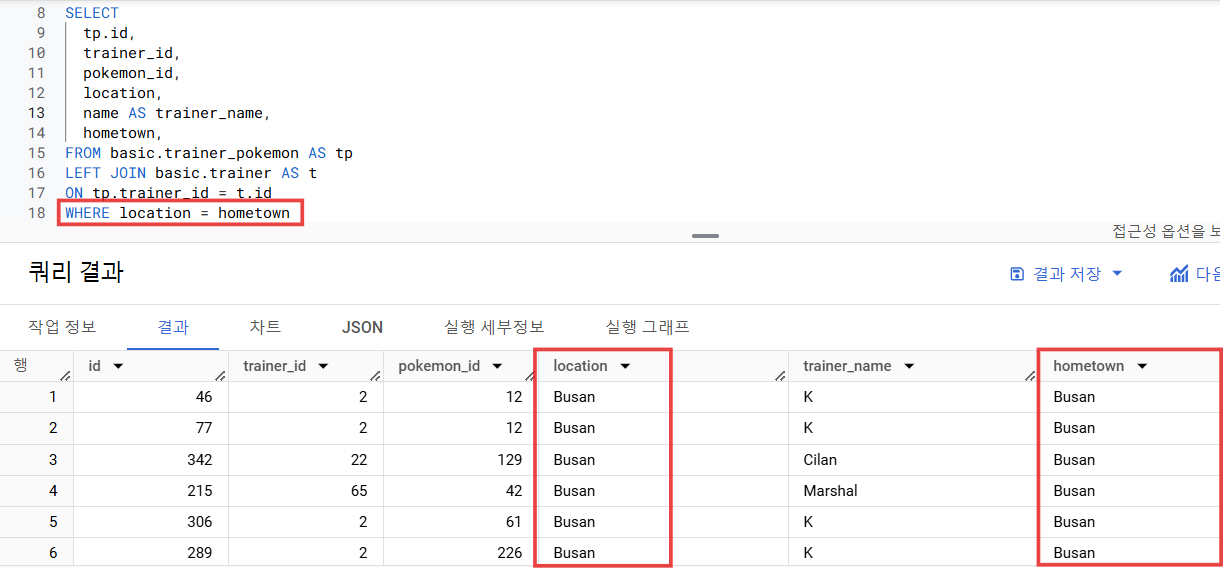
4) COUNT로 trainer_id 개수 세니까 43개로 나옴! (나머지 select는 주석 처리) ❎

▶강사님 풀이 과정✅
1) 원래는 trainer_pokemon을 왼쪽에 두고 푸시지만, 일부러 trainer를 왼쪽에 두고 푸는 걸 보여주심
- trainer처럼 메타 정보가 들어있는 테이블을 왼쪽에 두면, 아래 그림처럼 갑자기 데이터가 늘어난 것처럼 헷갈릴 수 있음 (ex. 원래 trainer 테이블에는 'Goh'가 1명인데, JOIN한 왼쪽 탭에는 'Goh'가 6명이나 나옴)
- trainer_pokemon을 왼쪽에 둬도 결과는 똑같긴 한데, 초반 컬럼에 나오는 정보들이 혼동을 줄 수 있다는 말!

2) ⚠️WHERE current_health IS NULL을 추가해서 한 번 조회해봄 → 아무 것도 안 나옴
- 즉, 모든 트레이너가 1번씩은 포켓몬을 잡아본 적 있다는 뜻 (현업에서 이런 식으로 NULL 있나 체크 잘 해야 함)
3) 그리고 역시 WHERE 조건 location = hometown 걸고, COUNT로 trainer_id 개수 세면 됨!
- 단, 강사님은 location IS NOT NULL 조건도 걸고 작업하심 (더 안전하게)
- COUNT에 DISTINCT 붙여줘야 중복 없이 트레이너 개수 출력 가능!! (이걸 놓침) ⇒ 정답은 28개!
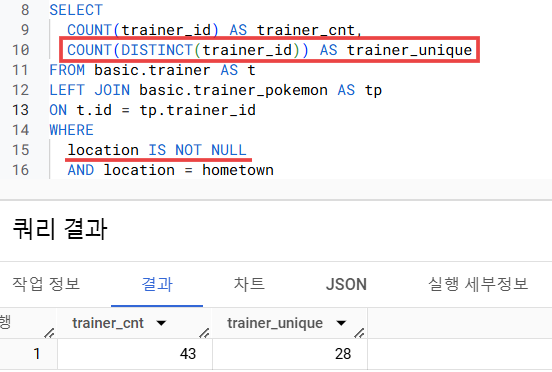
▶전체 코드
-- 쿼리 작성하는 목표, 확인할 지표 : hometown과 location이 동일한 트레이너 수
-- 쿼리 계산 방법 : JOIN -> Where 조건 걸고 Count
-- 데이터의 기간 :
-- 사용할 테이블 : trainer_pokemon, trainer
-- JOIN KEY : tp.pokemon_id = t.id
-- 데이터의 특징 :
SELECT
COUNT(trainer_id) AS trainer_cnt,
COUNT(DISTINCT(trainer_id)) AS trainer_unique
FROM basic.trainer AS t
LEFT JOIN basic.trainer_pokemon AS tp
ON t.id = tp.pokemon_id
WHERE
location IS NOT NULL
AND location = hometown;
--❎내 풀이 과정 --
SELECT
-- tp.id, COUNT할 때 주석처리
-- trainer_id,
-- pokemon_id,
-- location,
-- name AS trainer_name,
-- hometown,
COUNT(trainer_id) AS trainer_cnt
FROM basic.trainer_pokemon AS tp
LEFT JOIN basic.trainer AS t
ON tp.pokemon_id = t.id
WHERE location = hometown
문제 4. Master 등급인 트레이너들은 어떤 타입의 포켓몬을 제일 많이 보유하고 있을까요? (*보유했다의 정의는 1번 문제의 정의와 동일)
▶내 풀이 과정✅
1) 데이터 확인
- 트레이너 등급은 trainer 테이블에 있네.
2) (1번 문제처럼) '보유 중인' 조건으로 일단 trainer_pokemon 테이블 축소하고, trainer 테이블과 JOIN
- 주요 컬럼만 조회해봄 ➔ 엥 근데 null도 있네? ➔ 알고보니 ON에서 실수했음..
- 다시 제대로 JOIN함


3) 여기서 WHERE로 Master 등급만 필터링
- 맨 밑에 WHERE achievement_level = "Master"만 추가하면 됨 = 총 67행 나옴
- 아 근데 type 보려면 pokemon 테이블도 필요하네;; 추가로 연결하자

4) 지금까지 한 걸 다시 서브쿼리로 감싸고, pokemon과 JOIN

5) 이제 type1으로 그룹화해서 COUNT로 개수 세면 끝
- 서브쿼리 2번이나 쓰면서 id 중복되는 문제 발생 ➔ 그래서 그냥 t.id 빼버림 (어차피 trainer_id 있으니까)
- 고친 쿼리에 ORDER BY 추가해서 출력! = water 타입이 14개로 제일 많네!
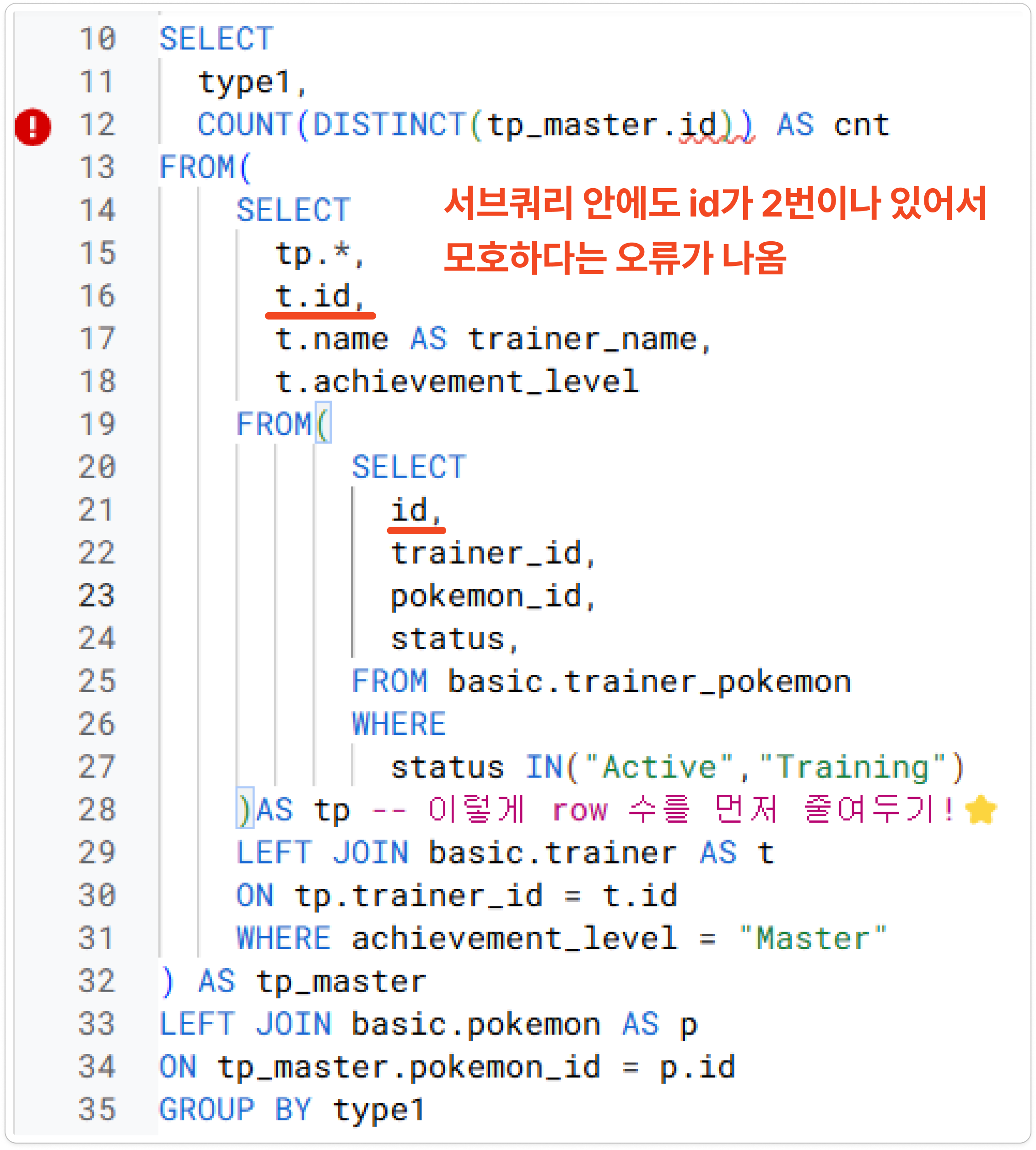

▶강사님 풀이 과정✅
1) 데이터 확인
- achievement_level은 trainer 테이블에 있고, type1은 pokemon 테이블에 있는데, 둘을 연결할 수 없음. 따라서 세 테이블 전부 JOIN이 필요하네!
- 이런 경우, JOIN에 가장 많이 관여하는 테이블을 기준 테이블로! (ex. trainer_pokemon)
2) tp 테이블에 p 테이블 붙이고, 이어서 바로 t 테이블도 붙임!
- 일단 SELECT *로 잘 결합됐는지 조회해봄
- 이랬으면 서브쿼리 2번이나 안 써도 됐는데ㅠ 데이터 확인을 처음에 확실하게 하고 시작해야한다는 것을 느낌

3) 여기서 WHERE로 Master 등급만 필터링
4) 그리고 type1으로 그룹화해서 COUNT하면 끝!
- ORDER BY로 가장 많은 것부터 출력 = water 타입이 14개로 제일 많음!

▶전체 코드
-- Master 등급인 트레이너들은 어떤 타입의 포켓몬을 제일 많이 보유하고 있을까요? (*보유했다의 정의는 1번 문제의 정의와 동일)
-- 쿼리 작성하는 목표, 확인할 지표 : Active or Training인 포켓몬들 + 잡은 트레이너가 Master이어야 함
-- 쿼리 계산 방법 : join
-- 데이터의 기간 :
-- 사용할 테이블 : trainer_pokemon, trainer, pokemon
-- JOIN KEY : id, trainer_id
-- 데이터의 특징 :
-- 보유했다의 정의는 status가 'Active', 'Training'인 경우를 의미
SELECT
type1,
COUNT(tp.id) AS pokemon_cnt
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status,
FROM basic.trainer_pokemon
WHERE
status IN("Active","Training")
) AS tp
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
LEFT JOIN basic.trainer AS t --연달아 2번 JOIN!
ON tp.trainer_id = t.id
WHERE t.achievement_level = "Master"
GROUP BY type1
ORDER BY 2 DESC
-- 내 풀이 과정 --
SELECT
type1,
COUNT(DISTINCT(tp_master.id)) AS cnt -- count는 습관적으로 distinct 붙여버리자
FROM(
SELECT
tp.*, -- 어차피 이 안에 trainer_id 있으니까 t.id는 빼자!
t.name AS trainer_name,
t.achievement_level
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status,
FROM basic.trainer_pokemon
WHERE
status IN("Active","Training")
)AS tp -- 이렇게 row 수를 먼저 줄여두기!⭐
LEFT JOIN basic.trainer AS t
ON tp.trainer_id = t.id
WHERE achievement_level = "Master"
) AS tp_master
LEFT JOIN basic.pokemon AS p
ON tp_master.pokemon_id = p.id
GROUP BY type1
ORDER BY cnt DESC
문제 5. Incheon 출신 트레이너들은 1세대, 2세대 포켓몬을 각각 얼마나 보유하고 있나요?
▶내 풀이 과정✅
1) 데이터 확인
- 이번에도 세 테이블 전부 필요함! (trainer와 pokemon을 연결해야 하기 때문)
2) 연속 2번 JOIN해서 셋 다 연결하는 것까지는 4번 풀이와 동일

3) 여기서 WHERE로 Incheon 출신만 필터링

4) 그리고 generation으로 그룹화해서 COUNT하면 끝! = 1세대 33마리, 2세대 10마리!
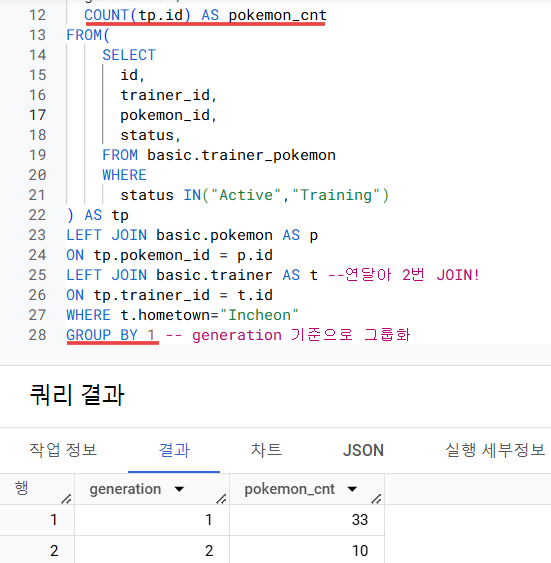
▶강사님 풀이 과정✅
1) 대부분 동일하고, 아래 세부 내용만 다름
- JOIN 2번 하실 때 trainer 테이블을 먼저 연결하심 (이건 순서 크게 상관없음)
2) 👨🏫데이터가 계속 업데이트 될 경우 주의사항
- ex) 만약 generation이 3,4, ...계속 나와도 1,2세대만 보고 싶다면? ⇒ WHERE에 generation IN (1,2) 추가해줘야 함!
- 이런 식으로, 쿼리 수정(리팩토링) 많이 안 해도 되도록 미래의 요구조건까지 생각해보면서 짜면 좋음!
▶전체 코드
-- Incheon 출신 트레이너들은 1세대, 2세대 포켓몬을 각각 얼마나 보유하고 있나요?
-- 쿼리 작성하는 목표, 확인할 지표 : hometown="Incheon"인 트레이너, generation으로 group by
-- 쿼리 계산 방법 : JOIN으로 셋 다 연결 -> Where 조건 걸고 Count
-- 데이터의 기간 :
-- 사용할 테이블 : trainer_pokemon, trainer, pokemon
-- JOIN KEY : tp.trainer_id = t.id / tp.pokemon_id = p.id
-- 데이터의 특징 :
-- 보유했다의 정의는 status가 'Active', 'Training'인 경우를 의미
--✅내 풀이 과정 --
SELECT
generation,
COUNT(tp.id) AS pokemon_cnt
FROM(
SELECT
id,
trainer_id,
pokemon_id,
status,
FROM basic.trainer_pokemon
WHERE
status IN("Active","Training")
) AS tp
LEFT JOIN basic.pokemon AS p
ON tp.pokemon_id = p.id
LEFT JOIN basic.trainer AS t --연달아 2번 JOIN!
ON tp.trainer_id = t.id
WHERE t.hometown="Incheon"
GROUP BY 1 -- generation 기준으로 그룹화📌Self-Feedback
- JOIN Key 설정할 때 테이블 실수 조심하자,,,
- 쿼리 짜기 전에 필요한(JOIN 해야할) 테이블들이 어떤 건지 확실하게 정의하고 들어가자!
🙏References
- 카일스쿨 님의 인프런 강의 (https://www.inflearn.com/course/%EC%B4%88%EB%B3%B4%EC%9E%90%EB%A5%BC-%EC%9C%84%ED%95%9C-%EB%B9%85%EC%BF%BC%EB%A6%AC-sql-%EC%9E%85%EB%AC%B8/dashboard) 를 듣고 정리한 내용입니다.
'SQL > BigQuery' 카테고리의 다른 글
| [SQL] 12. 연습문제 풀이 (0) | 2025.02.28 |
|---|---|
| [SQL] 11. 쿼리 가독성(WITH), 데이터 결과 검증 (0) | 2025.02.23 |
| [SQL] 9. 조건문 (CASE WHEN, IF) (0) | 2025.02.15 |
| [SQL] 8. 다양한 데이터 타입 (날짜 및 시간) (0) | 2025.02.13 |
| [SQL] 7. 다양한 데이터 타입 (CAST, 문자열) (1) | 2025.02.12 |