
Intro.
럭키백 이벤트로 히트 친 한빛마켓,, 너도 나도 수산물을 공급하겠다고 아우성 ,,
김 팀장🗣️
"이제는 7개의 생선 말고 새로운 생선도 추가될 거고, 수산물들이 오는 족족 분류모델을 업데이트 해야 해. 모든 생선이 도착할 때까지 마냥 기다릴 순 없으니까.. 기존 데이터를 유지하면서 새로운 데이터가 올 때마다 조금씩 훈련시킬 수 있겠어?" = 점진적 학습!
1. 확률적 경사 하강법
확률적 경사 하강법(SGD)
- 대표적인 '점진적 학습' 방법. (단, 선형회귀나 로지스틱처럼 ML/DL '알고리즘'이 아니라 그런 알고리즘들을 '최적화하는 방법'에 대한 거라고 보면 됨!)
- '경사 하강' : 가장 가파른 경사를 따라 조금씩 내려감. 목표지점 가까워질수록 더 조금씩! (한 번에 많이 내려가면 지나칠 수 있기 때문)
- '확률적' : 전체 샘플을 쓰지 않고, 훈련세트에서 딱 하나를 랜덤하게 골라서 훈련(가장 가파른 길 탐색)함.
= 전체 샘플 다 쓸 때까지 계속 하나씩 꺼내면서 조금씩 하강함.
- IF 샘플을 다 썼는데도 산을 다 내려오지 못했다면..?
- 다시 샘플 다 채워넣고, 다시 같은 방법으로 내려가면 됨! (보통 에포크 수백번 거침..)
- 에포크(epoch) : 훈련세트를 한 번 모두 사용하는 과정
미니배치 경사 하강법(minibatch-GD)
- 한 개씩만 꺼내는 게 못 미덥다면, 여러 개씩 꺼내서 경사하강법 수행 가능!
- 개수는 보통 2의 배수로 하는 것이 일반적.
배치 경사 하강법(batch-GD)
- 아예 샘플 몽땅 꺼내서 경사하강법 수행하는 것도 가능.
- 가장 안정적인 방법일 수는 있겠으나 but 메모리적 한계 때문에 잘 사용 X.

근데... 대체 어디를 내려간다는 거야? 이 '산'에 해당하는 게 뭔데...?
2. 손실 함수
손실함수 (Loss function)
- 조금씩 하강하는 그 산이 바로 '손실 함수' !!
- 특정 알고리즘이 얼마나 나쁜지를 측정하는 함수 → 당연히 값이 작을수록 좋음!
- 우리가 직접 만드는 일은 거의 없고, 이미 상황별로 정의되어있음.
분류에서의 손실함수
- 알다시피 분류는 '정확도'로 성능을 측정함
- but 정확도는 듬성듬성 끊기는 값이라서 손실함수로 사용할 수 없음 .. (* 손실함수는 미분가능해야 함!)
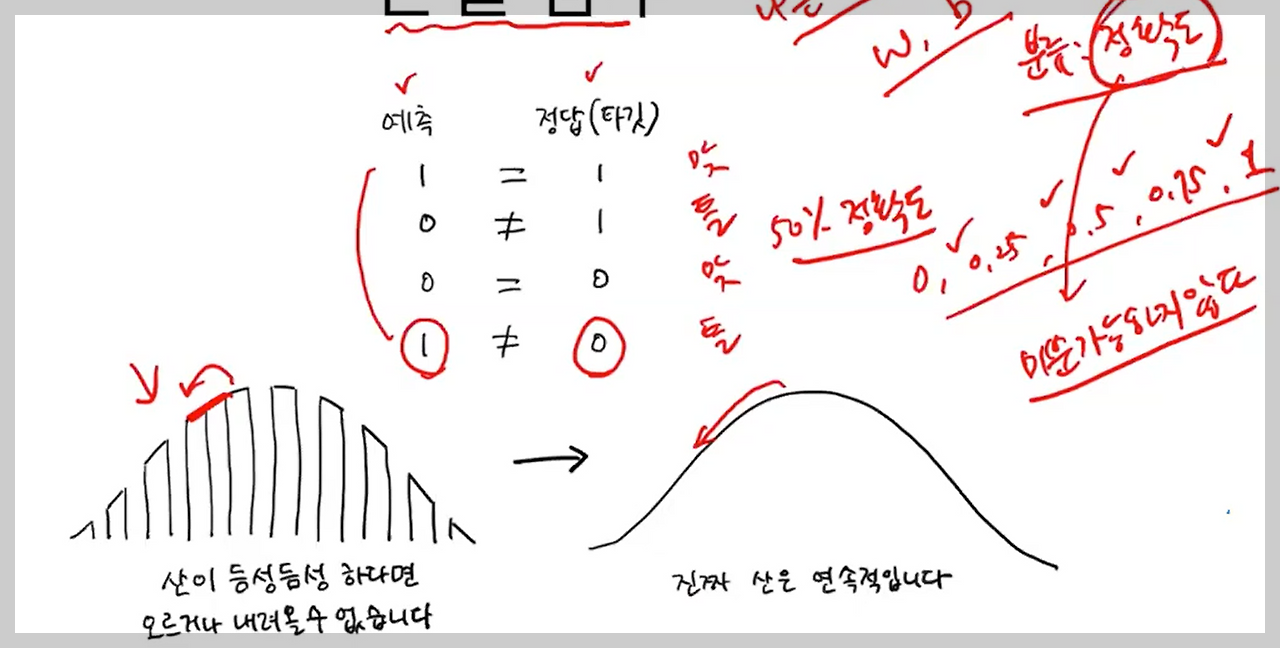
- 그래서 대안으로 가져온 게 바로 로지스틱 손실함수! (=이진 크로스엔트로피 손실함수)
- 1) 정답과 가까운 예측은 '낮은 손실'로 표현되고, 먼 예측은 '높은 손실'로 표현되도록 계산
- 2) 로그함수를 적용해 '높은 손실'일수록 아주 큰 양수값이 되도록! (p.204-206)

회귀에서의 손실함수
- 평균 절댓값 오차 : 타깃에서 예측을 뺀 절댓값을 모든 샘플에 평균한 값
- 평균 제곱 오차 : 타깃에서 예측을 뺀 값을 제곱한 후 모든 샘플에 평균한 값
- 🆚 분류와 달리, 손실함수와 성능 측정지표가 동일한 셈.
| 성능 측정지표 | 손실 함수 | |
| 분류 | 정확도 | 로지스틱 손실함수 |
| 회귀 | 평균 절댓값 오차 or 평균 제곱 오차 | 평균 절댓값 오차 or 평균 제곱 오차 |
우리는 이미 손실함수를 직접 계산할 필요 없이 사이킷런, 텐서플로 등에 구현되어있는 것을 사용하면 됨.
하지만 손실함수가 무엇인지, 왜 정의해야 하는지 이해하는 것이 중요⭐
3. SGDClassifier
그럼 배운 것을 바탕으로, 확률적 경사하강법을 이용한 '분류' 모델을 만들어보자!
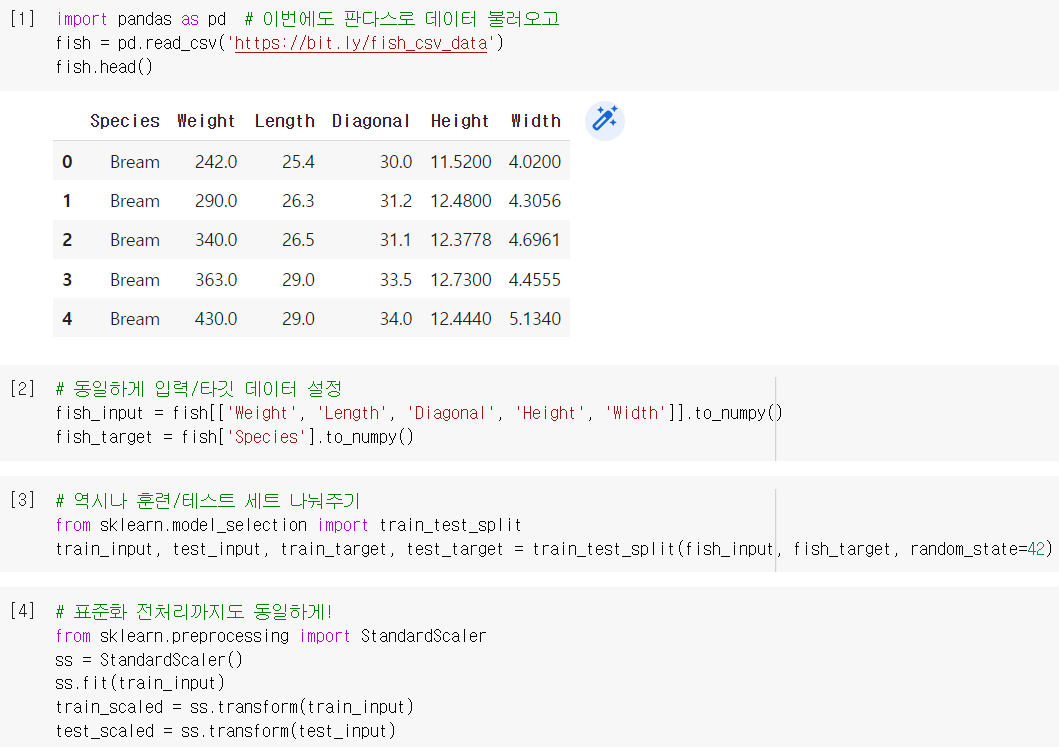
데이터 준비
- 이전과 동일한 방식으로 데이터 준비 (표준화 전처리 필수!)
모델 훈련
- `SGDClassifier()` : 확률적 경사하강법을 제공하는 분류용 클래스
- `loss` : 손실함수의 종류를 지정하는 매개변수 ('log' = 로지스틱 손실함수)
- `max_iter` : 수행할 에포크 횟수를 지정하는 매개변수 (일단 10 에포크만 해봄)

점진적 학습
- `.partial_fit()` : 모델을 이어서 훈련시키는 메소드 (호출할 때마다 1 에포크씩)
- 방금 10 에포크 훈련한 것에 이어서 훈련
- 그냥 fit()하면 이전 학습 내용 다 초기화하고 다시 하게 됨 ❗

그렇다면, 몇 에포크나 더 훈련시켜야 할까? 무작정 많이 하면 될까...?
최적의 에포크 찾기
- 에포크가 적으면 훈련세트를 덜 학습해 과소적합되지만, 무작정 에포크를 늘려서 많이 훈련하면 또 과대적합이 되어버림...ㅠ
- ➡️과대적합이 시작되기 전에 훈련을 멈춰버리자! = 조기 종료(Early stopping)

- 300번의 에포크까지 훈련해보고 그에 따른 정확도(score)를 구해보니...
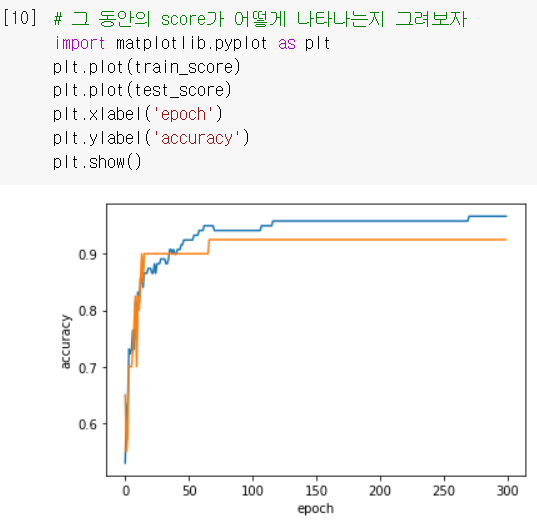
- 100 뒤로 넘어가면 갭이 점점 커짐 (=과대적합) → 최적의 에포크를 100으로!
- `tol` : 향상될 최솟값을 지정하는 매개변수 (SGD는 일정 에포크 동안 성능 향상 없으면 자동으로 멈춤)

good! 정확도 점수가 처음보다 많이 향상됨! 오늘도 문제해결 완료!
➕플러스 알파
➊ 또 다른 손실함수
- 분류를 위한 손실함수가 '로지스틱 손실함수'뿐인 건 아니다.
- `loss='hinge'` : 원래 이게 loss 매개변수의 기본값인데, 서포트 벡터 머신이라는 다른 알고리즘을 위한 손실함수라는 정도는 알고 있자. (= 힌지 손실함수)
➋ SGDRegressor
- 우리가 배운 게 확률적 경사하강법을 사용한 '분류'모델이라면, 이건 '회귀'모델!
- loss의 기본값은 제곱 오차를 나타내는 `'squared_loss'`이며, SGDClassifier에서 배운 매개변수들 다 동일하게 사용된다
🤔 Hmmmm...
204p. 여기 예시에서 말하는 '예측확률'은 '정답과 일치할 확률'이 아님 !!
이진분류이기 때문에, '양성 클래스일 확률' 을 의미함! = 정답(1)일 확률 🆗
213p. 근데 이 SGD의 사용 과정이 이해가 잘 안 가네요.. 이걸로 최적화해놓고 나서, 다시 sc= LogisticRegression 로 분류 문제를 푸는 건가요...?
아하..! 그런 게 아니라, 이미 똑같은 로지스틱 회귀 모델인데 그 세부설정으로 SGD가 있는 느낌이네 → 그니까, 사실상 4-1에서 로지스틱 모델 훈련한 거랑 같은데, 얘는 훈련세트를 업데이트 해가면서 할 수 있다는 장점을 추가로 가지고 있다 정도로 이해해도 괜찮을까요..?
👨🏻🏫이 장에서는 경사하강법을 배우기 때문에 SDGClassifier를 사용합니다. SGDClassifier(loss='log')와 LogisticRegression 모두 로지스틱 회귀를 구현하지만 다른 알고리즘을 사용합니다. 🆗
🤓 To wrap up...
처음에 로지스틱 손실함수에서 '예측확률'의 의미를 혼동해서 한참을 헤멨다ㅠ 강의 영상과 질문 찾아보고 다행히 해결했는데, 나랑 똑같은 착각을 하신 분들이 꽤나 있으신 거 같았다.. 역시 아 다르고 어 다른 통계학 속 말들..^^ 손실함수를 왜 정의하는지와 어떤 논리로 경사하강법을 쓰는지는 알겠는데, 아직 이게 어떻게 점진적 학습에 사용되는지 그 구체적인 느낌은 100% 이해하진 못한 것 같다. 아마 프로젝트를 하든가 나중에 7장에서 신경망 배운다니까 그때 되면 이해되지 않을까.. 소망해본다...!
인기 폭발한 한빛 마켓은 새로 들어오는 생선 데이터들을 그때그때 업데이트 할 수 있는 실시간 학습 모델이 필요 → 점진적으로 학습하는 확률적 경사하강법을 사용해보자 → 분류 문제니까 로지스틱 손실함수로 정의하고, 거기에 확률적 경사하강법(SGDClassifier) 적용! → 확실히 훈련을 점점 반복(partial_fit)할수록 정확도가 높아지네 → 반복문을 통해서 최적의 에포크를 찾아보니 100이 적당할 듯 → 100 에포크로 설정하고 하니 최적의 생선 분류 모델이 완성!

*본 포스팅은 이전에 Velog(https://velog.io/@simon919)에서 작성했던 글을 Tistory로 옮긴 것입니다.
'ML & DL > 머신러닝 기초' 카테고리의 다른 글
| [혼자 공부하는 머신러닝+딥러닝] 5-2. 교차 검증과 그리드 서치 (0) | 2025.02.16 |
|---|---|
| [혼자 공부하는 머신러닝+딥러닝] 5-1. 결정 트리 (0) | 2025.02.15 |
| [혼자 공부하는 머신러닝+딥러닝] 4-1. 로지스틱 회귀 (0) | 2025.02.10 |
| [혼자 공부하는 머신러닝+딥러닝] 3-3. 특성 공학과 규제 (1) | 2025.02.08 |
| [혼자 공부하는 머신러닝+딥러닝] 3-2. 선형 회귀 (0) | 2025.02.07 |